[김건우][AI 기초와 활용] 4. chat-GPT를 활용한 pandas 데이터 편집
작성자 : 김건우
(2024-03-24)
조회수 : 13546
|
[YOUTUBE] [김건우][AI 기초][2/2] 왜 엑셀이 아닌 파이썬을 써야할까? - GPT와 함께하는 판다스 데이터 편집 (youtube.com) [CODE & 데이터] 유튜브 설명란 참조 지난 시간에 이어서 pandas 라이브러리를 통해 붓꽃 데이터 세트를 편집하는 과정을 다루어 보고자 합니다. |

|
생성형 AI에는 여러 종류가 있지만 저희는 챗GPT를 사용하려고 해요. 사용전에 챗GPT가 어떤 건지 알아야 하겠죠. 챗GPT는 대화형 인공지능인데요. 콜롬비아 판사가 판결문으로 챗GPT를 활용하기도 했고, 미국하원 의원 제이크는 연설 의회에서 쓸 연설문을 쓰기도 하였을 만큼 성능이 뛰어난데요. 우리가 질문하면 습득한 정보를 기반으로 원하는 문서나 코드를 창작하거나 깔끔하게 정리해서 답변을 해주게 됩니다. 저희는 GPT를 이용해서 원하는 코드를 작성하는데 활용해 보고자 합니다. 기본적인 인터페이스와 회원가입부터 사이트 접속까지 챗-GPT 에 대한 친절한 설명은 국립중앙과학관에서 제공하는 유튜브 링크를 영상 하단에 걸어두었습니다. |

|
코딩을 통해서 기존에 받아둔 '아이리스 데이터'를 편집해 보겠습니다. 우리는 기존에 csv를 확인했을 때 각 열의 데이터들이 어떤 데이터인지 알 수가 없었죠. 그래서 우리는 name.data파일을 통해서 확인해야 했는데요. pandas에서 열 이름을 붙여주고 class열을 맨 앞으로 이동해 보도록 하겠습니다. 이후에 csv로 다시 저장하는 것이 오늘의 주제입니다. |

|
가장 먼저 csv를 확인하기 위해 판다스 라이브러리를 불러와야 하겠죠. 운영체제와 상호작용을 위한 os 라이브러리도 필요할 거에요. 임포트 판다스, 임포트 os로 필요한 라이브러리를 불러오겠습니다. 그리고 컴퓨터에 어느경로에 파일이 저장되어 있고 어떤 파일을 열어야 할지 알려줘야 할텐데요. path라는 변수를 사전에 준비한 iris data 폴더의 경로로 설정하겠습니다. 이제 판다스로 csv를 읽어와야 할텐데요. 사실 그 다음에 첫 번째줄부터 코드를 어떻게 작성해야 하는지 잘 모르겠죠? 저도 함수를 거의 외우지 않아서 생각이 나지 않을 때가 많은데요. 하지만 우리가 무엇을 할지만 정한다면 생성형 AI에게 도움을 받을 수 있어요. |

|
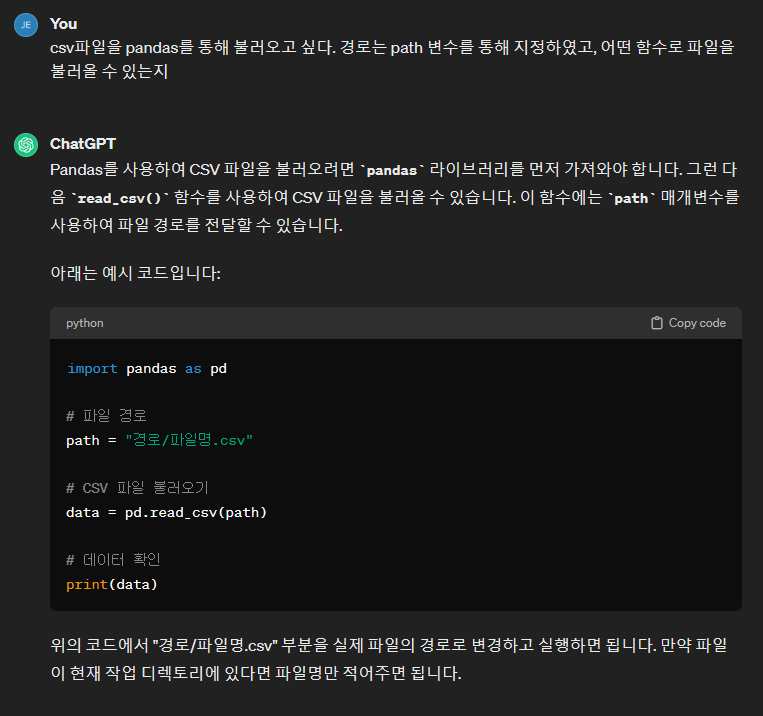
생성형 AI에게 질문을 할때는 우리가 얻고자 하는 답변을 얻으려면 주어진 조건과 환경을 정확하게 전달해 주는 것이 좋을 거에요. 사진처럼 저는 csv파일 불러오는 함수가 알고 싶었기 때문에, pandas를 사용해 csv를 읽고 싶다고 이야기를 하였는데요. 경로는 저만 아는 정보이므로 path변수로 경로를 이미 설정해 두었다고 조건을 걸었어요. 그리고 함수를 알려달라고 질문을 하였습니다. 답변으로 우리가 원하는 “read_csv 함수를 사용하여 CSV 파일을 불러올 수 있습니다.”라고 이야기를 하네요. 하지만 답변에서는 단순하게 read_csv 라는 함수를 사용하면 된다고 하는데요. 지난시간에 배웠던 내용에 의하면 메서드 안에는 여러가지 옵션으로 선택할 수 있는 파라미터란게 있었죠? 좀 더 자세히 설명을 해달라고 질문을 해보겠습니다. |


|
우리가 설정할 수 있는 옵션에 무엇이 있는지, “read_csv() 메소드의 주요 파라미터들에 대해 설명해줘.”라고 질문해 볼게요. 답변을 보니까 자주 사용되는 주요 파라미터에 대해서 쭉 간단한 설명과 함께 나열해 주었네요. 분명 이 많은 파라미터를 다쓰진 않을 거에요. 상식이라 생각하고 몇 개만 보고 가볼게요. 파일 패스라는 것은 경로겠죠. 당연히 필요할 거구 저희는 사전에 변수로 path를 통해 지정해 놓았습니다. sep이라는 것은 seperated의 약자일 거라구 유추가 되는데요. 구분자로 디폴트 값은 쉼표라고 하네요. 저희는 csv를 사용한다고 저번 영상에서 이야기 했었죠. Csv는 쉼표로 구분된 데이터니까 따로 설정해주지 않아도 될거에요. Header는 첫번째 행을 열 이름 목록으로 지정해준다고 하는데요. 저희가 가진 파일은 열이름이 없으니까 none으로 설정해야 할거에요. 마지막으로 하나만 더 볼게요. Skiprows는 몇줄을 건너뛰고 읽을건지 지정한다고 하네요. 저희는 첫줄부터 읽어야 하니까, skiprows를 설정할 필요가 없을거에요. 메소드 내의 파라미터가 익숙치 않다면 조건을 주고 파라미터까지 설정해서 GPT에게 코딩을 부탁할 수 있어요. |
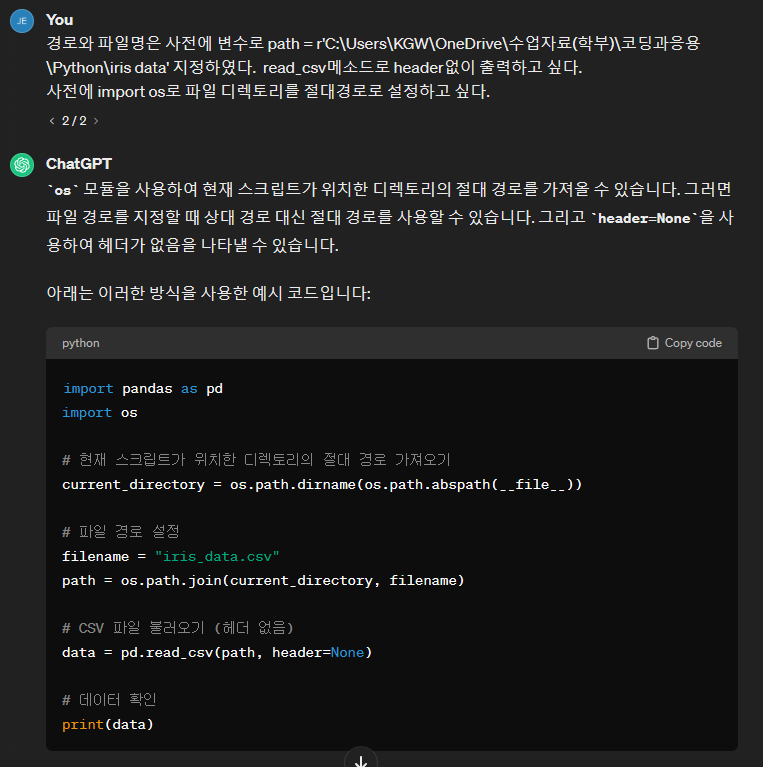
| 사전에 저희가 지정한 변수를 알려주고 앞서 보여드린 파라미터에서 무엇을 쓰고 싶은지 질문해볼게요. 저는 “경로와 파일명은 사전에 변수로 path = rows'\파일경로'로 지정했다. read_csv메소드로 header없이 출력하고 싶다.”라고 질문을 했습니다. 답변으로 코드를 제시해 주네요. 굳이 3줄에 걸쳐서 절대경로를 상세히 적어둘 필요는 없어 보이니 저는 답변을 참고해서 한줄로 가져가겠습니다. |
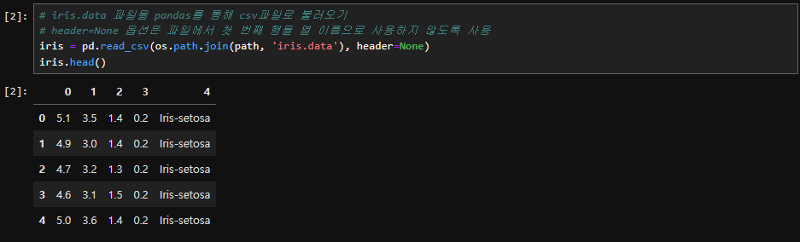
| 저는 읽을 데이터를 iris 라는 변수에 저장하겠습니다. Iris를 출력하면 메모장에서 확인한 것보다 구분하기 쉽게 index가 생성되어 출력되는 것을 볼 수 있네요. 데이터프레임은 150행 5열로 구성된 데이터임을 알 수 있죠. 그리고 컴퓨터는 우리처럼 1부터 숫자를 세지 않고 0부터 시작하게 됩니다. 출력결과를 위에서 5줄만 출력되도록 프린트 대신 head()메소드를 이용할 수도 있습니다. |
|
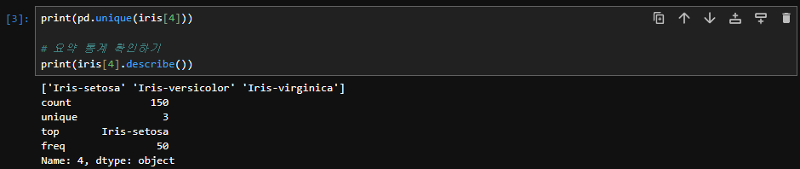
이제 출력된 결과에서 우리는 붓꽃의 종류가 어떠한 것들이 있는지 알고 싶은데요. 일일이 확인하기에 너무 번거롭습니다. 그래서 판다스의 유니크 함수를 이용하면 우리는 5번째 열의 고유한 값들을 추출할 수 있게 됩니다. describe( ) 메서드는 해당열에 대한 요약 통계를 출력하게 되는데요. 간략하게 기본적인 정보를 확인할 수 있습니다. decibe 메서드에는 고유한 값들과 통계적 정보를 통 데이터를 이해하는데 도움을 받을 수 있어요.
|
|
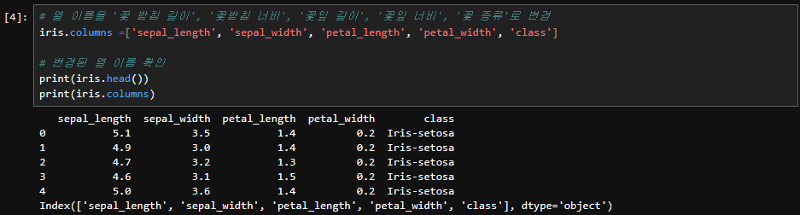
pandas에서 불러온 csv파일은 열 제목이 번호로 되어있는데요. 이를 구분하기 쉽도록 각각의 열이 어떠한 데이터인지 이름을 변경해 주도록 하겠습니다. 열 이름을 columns 객체 속성에서 '꽃 받침 길이', '꽃받침 너비', '꽃잎 길이', '꽃잎 너비', 그리고 '꽃 종류'로 변경해 주겠습니다. 프린트 함수를 통해 변경이 되었는지 확인해 볼게요. print(iris.columns)는 iris의 열 이름을 출력합니다. 데이터 프레임을 출력하는것보다 columns 속성으로 출력하는게 더 확인하기 쉽네요. 그리고 출력 결과는 열 이름이 포함된 리스트 형태로 제공되는 것을 볼 수 있었습니다. |

|
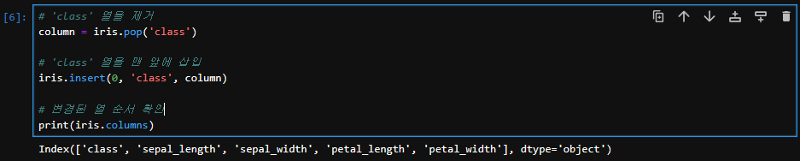
이제 ‘class’ 열을 보기 쉽도록 맨 앞 열로 보내주도록 하겠습니다. 어떻게 코드를 구성해야 할까요? 생각해 보겠습니다. 저라면 데이터프레임의 모든 열을 선택하고 직접 원하는 순서대로 리스트를 입력할 것 같습니다. 아니면 우리가 흔히 쓰는 ‘class’열을 잘라내기 하고 붙여넣기 하는 방법도 있겠네요. 첫번째로 loc속성을 사용하는 방법입니다. Loc 속성은 행과 열을 선택하기 위해 사용하는 메서드입니다. 복잡해 보이지만 하나하나 풀어볼게요. 먼저 별표 연산자는 리스트를 펼쳐주는 역할을 하게 되는데요. 맨 앞에 ‘class’ 열을 넣습니다. 이제 ‘class’열을 제외한 나머지 열을 선택해야 하는데요. 이를 위해 아이리스 닷 컬럼스에 서브 슬라이스 콜론 -1로 마지막 열을 제외한 모든 열 이름을 선택합니다. 그리고 * 연산자를 이용해서 선택된 열들을 개별 인수로 분리해주겠습니다. 참고로 콜론(:)은 모든 행을 의미합니다. 두번째로 잘라내고 붙여 넣어 보겠습니다. 데이터프레임에서 ‘class’열을 제거하고 맨 앞에 삽입하여 열순서를 변경해 보겠습니다. Pop 메서드는 특정 열을 제거하고 해당열을 반환합니다. 그리고 해당 열을 column이라는 변수에 저장하겠습니다. 여기 까지만 한다면 ‘class’열이 제거된 새로운 데이터 프레임이 생성될 겁니다. Insert 메서드는 특정 위치에 새로운 열을 삽입하는 기능을 합니다. 'class' 열을 맨 앞인 인덱스 0번째에 삽입하겠습니다. 두번째 인자는 열의 이름을 지정했고 세번째 인자에서 삽입될 열의 데이터를 지정하였습니다. 지금까지 데이터를 불러오고 편집해 왔는데요. 이렇게 우리가 해온 리스트 객체를 특정범위로 선택하고 편집하는 것을 ‘슬라이싱’ 이라고 합니다.
|
![]()
| 이렇게 편집한 csv를 기존에 path 변수로 설정한 경로로 iris.csv 이름으로 저장해 보겠습니다. To_csv 함수를 이용해서 파일을 저장이 가능합니다. |
|
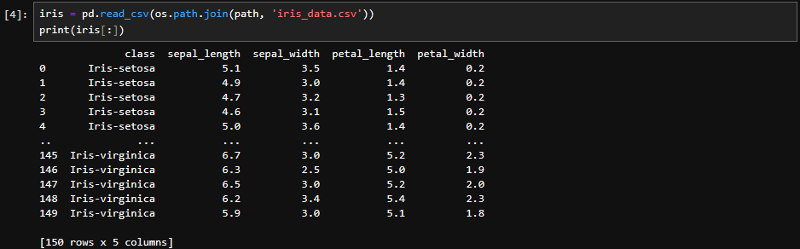
저장한 파일을 다시 처음처럼 read_csv 메서드로 다시 불러와 볼게요. Head() 함수로 확인해 보니, 우리가 열이름을 지정하고 열순서를 변경한 대로 저장되어 있는 것을 확인이 가능하네요. 양식은 다르지만, 프린트함수에 인덱스로 불러올 수도 있죠. 마지막 5행도 iris 닷 서브슬라이스 -5콜론으로 확인이 가능하네요.
지금까지 판다를 이용한 데이터 편집을 다루어 보았습니다. 다음 시간에는 편집한 데이터를 이용해 데이터 시각화를 배워보도록 하겠습니다. |