2006년 이전에는 심층 학습(Deep Learning)에 대한 이해의 부족으로 인해,
신경망(Neural Network)이 다층인 경우 학습이 제대로 이루어지지 않았다.
2006년 제프리 힌튼(Geoffrey Hinton)은
깊은 신경망이 학습에 실패하는 이유가 가중치의 초기값이 부적절하기 때문이라는 것을 발견했고,
그는 층별 사전훈련(layer-wise pre-training) 방법인
오토인코더(AutoEncoder)라는 혁명적인 기계학습(Machine Learning) 방식을 제안하였다.
오토인코더는 "깊은" 신경망도 효과적으로 학습시킬 수 있음을 보여주었고,
AI 겨울을 끝내는 신호탄이 되었다.
2) 왜 오토(Auto)인가?
오토(Auto = Self)란 최종 출력(Output)이 최초 입력(Input)을 재현(Auto)하기 때문에 붙여진 이름이다.
Autoencoder는 입력 데이터를 압축하여 저차원 표현으로 인코딩한 후, 다시 이를 복원하는 방식의 비지도 학습 모델이다.
입력과 출력이 동일하도록 학습되며, 주로 데이터 압축, 노이즈 제거, 이상 탐지 등의 응용에 활용된다.
오토인코더(Autoencoder)는 입력층과 출력층이 동일한 네트워크에 데이터를 입력하여 비지도학습을 하는 것이다.
인코더(Encoder)를 통해 입력 데이터에 대한 특징을 추출하고,
디코더(Decoder)를 통해 원본 데이터를 재구성하는 학습을 한다.
3) 오토인코더의 원래 목적은?
다층신경망 가중치의 좋은 초깃값을 얻는 목적으로 이용된다.
인코더와 디코더가 중요한 이유는 데이터 압축 때문이다.
영상 데이터처럼 의미 없는 부분이 많은 데이터는 중요한 부분만 추려낸 후에도,
그 데이터로 원본을 복원할 수 있어
오토인코더가 딥러닝에서 중요한 모델로 자리 잡고 있다.
02. 구성
오토인코더(Autoencoder)는 입력 데이터를 저차원 표현으로 압축(인코딩)하고,
다시 이를 원래 차원으로 복원(디코딩)하는 방식의 신경망 구조이다.
이 과정에서 데이터의 중요한 특징만을 남기고 불필요한 요소를 제거한다.
1) 인코더 (Encoder)
입력 데이터 \( x \)를 잠재 공간(Latent Space) 변수 \(z\)로 압축
데이터의 핵심 특징을 추출하는 역할
MLP, CNN, RNN 등 다양한 구조로 구현 가능
수식:
\[ z = f_{\theta}(x) \]
여기서 \( f_{\theta} \)는 인코더 함수, \( \theta \)는 학습 가능한 파라미터
2) 잠재 공간 (Latent Space)
잠재 공간(Latent Space)은 오토인코더의 중간 표현으로, 입력 데이터의 압축된 형태를 나타낸다.
차원 축소: 일반적으로 입력보다 낮은 차원, \( \text{dim}(z) < \text{dim}(x) \)
특징 추출: 데이터의 본질적인 특성을 학습
정보 병목(Information Bottleneck): 불필요한 정보는 제거되고 중요한 정보만 유지
연속적 표현: 유사한 입력은 잠재 공간에서도 가까이 위치
MNIST 데이터셋의 숫자 탐지를 위한 오토인코더의 잠재 공간 비교
출처: DOI:10.48550/arXiv.2004.07543
Trained Autoencoder (왼쪽): 일반적인 오토인코더가 생성한 잠재 공간이다. 숫자별로 군집(Cluster)을 이루고 있지만, 경계면에서 서로 겹치거나 섞여 있는 모습이 관찰된다.
Classifier / ReGene Classifier (오른쪽): 분류기(Classifier) 기반의 오토인코더가 생성한 잠재 공간이다.
왼쪽보다 숫자들 사이의 거리가 더 명확하고 깔끔하게 분리되어 있다.
이는 해당 모델이 각 숫자의 고유한 특징을 더 잘 구별하여 압축했음을 의미한다.
3) 디코더 (Decoder)
잠재 표현 \( z \)를 기반으로 입력 데이터 \( x' \)를 복원
원본과 유사한 출력을 생성하는 것이 목표
수식:
\[ \hat{x} = g_{\phi}(z) \]
여기서 \( g_{\phi} \)는 디코더 함수, \( \phi \)는 학습 가능한 파라미터
03. 수학적 정의
오토인코더의 전체 과정:
\[ \hat{x} = g_{\phi}(f_{\theta}(x)) \]
목적: 입력 \( x \)와 재구성된 출력 \( \hat{x} \)의 차이를 최소화
최적화 문제:
\[ \theta^*, \phi^* = \arg\min_{\theta, \phi} \mathcal{L}(x, \hat{x}) \]
여기서 \( \mathcal{L} \)은 손실 함수 (Loss Function)
오토인코더는 재구성 오차(Reconstruction Error)를 최소화하도록 학습된다.
이는 입력 데이터와 복원된 데이터 사이의 차이를 측정하는 것이다.
04. 학습 과정
오토인코더는 입력과 출력의 차이를 최소화하는 방향으로 학습되며, 일반적으로 다음과 같은 손실 함수를 사용한다.
1) 손실 함수
A. 평균 제곱 오차 (MSE: Mean Squared Error):
\[ \mathcal{L}_{\text{MSE}}(x, \hat{x}) = \frac{1}{n} \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 \]
사용처: 연속형 데이터 (이미지, 신호 등)
B. 이진 교차 엔트로피 (BCE: Binary Cross-Entropy):
\[ \mathcal{L}_{\text{BCE}}(x, \hat{x}) = -\frac{1}{n} \sum_{i=1}^{n} \left[ x_i \log(\hat{x}_i) + (1-x_i) \log(1-\hat{x}_i) \right] \]
사용처: 이진 데이터 (0 또는 1로 정규화된 데이터)
실제 레이블이 1인 경우, 손실은 주로 클래스 1에 대한 예측 확률이 1.0에 얼마나 가까운지에 따라 영향을 받는다.
실제 레이블이 0인 경우, 손실은 클래스 1에 대한 예측 확률이 0.0에 얼마나 가까운지에 따라 영향을 받는다.
단일 인스턴스에 대한 이진 교차 엔트로피 손실 출처: https://www.geeksforgeeks.org/machine-learning/what-is-cross-entropy-loss-function/
C. 평균 절대 오차 (MAE: Mean Absolute Error):
\[ \mathcal{L}_{\text{MAE}}(x, \hat{x}) = \frac{1}{n} \sum_{i=1}^{n} |x_i - \hat{x}_i| \]
사용처: 이상치에 강건한 모델이 필요할 때
PCA와 오토인코더의 비교 출처: Nugroho, Herminarto. (2020). Fully Convolutional Variational Autoencoder For Feature Extraction Of Fire Detection System. Jurnal Ilmu Komputer dan Informasi. 13. 10.21609/jiki.v13i1.761.
2) 이상 탐지 (Anomaly Detection)
정상 데이터에 대한 재구성 오류는 작지만, 이상치에 대해서는 복원 오차가 크게 나타남
탐지 방법: 재구성 오차가 임계값을 초과하면 이상으로 판단
이상 점수 (Anomaly Score):
\[ A(x) = \mathcal{L}(x, \hat{x}) = \|x - \hat{x}\|^2 \]
판별 규칙:
\[ \text{Anomaly if } A(x) > \tau \]
여기서 \( \tau \)는 임계값 (threshold)
금융 사기 탐지, 네트워크 보안, 의료 이상 진단 등 다양한 분야에 활용됨
장점: 레이블이 없는 정상 데이터만으로 학습 가능
오토인코더 기반 이상 탐지/분할의 개념 출처: Baur, Christoph & Denner, Stefan & Wiestler, Benedikt & Albarqouni, Shadi & Navab, Nassir. (2020). Autoencoders for Unsupervised Anomaly Segmentation in Brain MR Images: A Comparative Study. 10.48550/arXiv.2004.03271.
A) 정상 샘플만을 사용한 모델 학습
B) 이상을 포함할 수 있는 입력 샘플의 오류가 있는 재구성으로부터의 이상 분할
3) 노이즈 제거 (Denoising)
입력 데이터에 노이즈를 추가한 뒤, 원본에 가까운 출력을 복원하도록 학습
이미지 복원, 음성 신호 정제 등에 사용
응용 분야:
의료 영상 개선 (CT, MRI 노이즈 제거)
오래된 사진 복원
음성 인식 전처리
오토인코더를 사용한 이미지 노이즈 제거 출처: https://levelup.gitconnected.com/unsupervised-deep-learning-using-auto-encoders-4813bec64d
4) 생성 모델 (Generative Model)
일반적인 오토인코더와 달리, 데이터를 특정 '점'이 아닌 '확률 분포'로 압축하는 것이 특징이다.
변분 오토인코더(Variational Autoencoder, VAE)는 확률적 구조를 도입하여 샘플 생성이 가능
신경망 기반 생성 모델의 기초 구성으로도 활용됨
생성 과정:
사전 분포 \( p(z) \)에서 잠재 변수 \( z \) 샘플링
디코더를 통해 \( \hat{x} = g_{\phi}(z) \) 생성
응용: 얼굴 생성, 약물 분자 설계, 텍스트 생성
변분 오토인코더를 사용하여 이미지를 생성하는 방법 출처: https://theaisummer.com/Autoencoder/
인코더 (Inference): 입력 이미지($x$)를 받아 잠재 공간의 평균($\mu$)과 표준편차($\sigma$)를 추론한다. 이는 $q_\phi(z|x)$라는 확률 모델로 표현된다.
잠재 분포 (Latent Distribution): 중앙의 정규분포 그래프는 압축된 정보가 가우시안 분포 형태를 띠고 있음을 보여준다.
이 분포 덕분에 모델은 학습하지 않은 데이터 사이의 값도 자연스럽게 생성할 수 있는 능력을 갖추게 된다.
디코더 (Generative): 잠재 분포에서 샘플링된 변수($z$)를 사용하여 원래의 이미지를 복원($\tilde{x}$)한다. 이는 $p_\theta(x|z)$ 모델에 해당한다.
07. 구현 예시
1) MNIST 데이터셋의 숫자 탐지
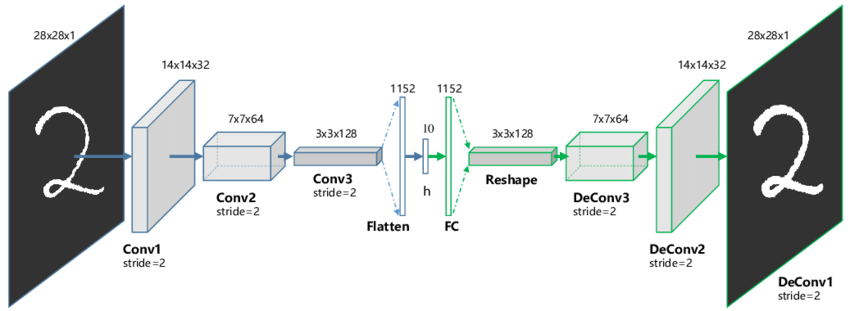
MNIST 데이터셋의 숫자 탐지를 위한 오토인코더 구조 출처: 위키독스 (wikidocs.net)
인코더(Encoder): 데이터 압축 그림 왼쪽의 파란색 영역으로, 입력 이미지의 특징을 추출하여 작은 차원으로 압축하는 과정
Input (28x28x1): MNIST 데이터셋과 같은 가로 28, 세로 28 픽셀의 흑백(채널 1개) 숫자 '2' 이미지
합성곱(Convolution) 계층:
stride=2를 사용하여, 각 단계를 거칠 때마다 이미지의 가로·세로 크기를 절반으로 줄인다.
• 1단계(Conv1): 28x28x1 → 14x14x32 (이미지 축소)
• 2단계(Conv2): 14x14x32 → 7x7x64 (이미지 축소)
• 3단계(Conv3): 7x7x64 → 3x3x128 (이미지 축소)
Flatten: 3차원 데이터($3 \times 3 \times 128 = 1,152$)를 1차원 벡터로 길게 펼친다.
잠재 공간(Latent Space) 그림 중앙의 가장 좁은 부분
h (Dimension = 10):
1,152개의 데이터를 단 10개의 숫자로 압축했다. 이를 '잠재 변수(Latent Variable)'라고 하며, 숫자 '2'가 가진 핵심적인 특징(기울기, 굵기 등)만을 응축해서 담고 있다.
디코더(Decoder): 데이터 복원 그림 오른쪽의 녹색 영역으로, 압축된 정보로부터 원래 이미지로 다시 재구성하는 과정
FC(Fully Connected): 10개의 숫자를 다시 1,152개의 숫자로 확장한다.
Reshape: 1차원 벡터를 다시 3x3x128의 3차원 형태로 바꾼다.
역합성곱(Deconvolution) 계층:
인코더와 반대로 이미지의 크기를 다시 키운다.
stride=2를 사용하여, 각 단계를 거칠 때마다 이미지의 가로·세로 크기를 2배로 키운다.
• 1단계(Conv1): 3x3x128 → 7x7x64 (이미지 확대)
• 2단계(Conv2): 7x7x64 → 14x14x32 (이미지 확대)
• 3단계(Conv3): 14x14x32 → 28x28x1 (이미지 확대)
Output (28x28x1): 최종적으로 생성된 이미지이다. 입력된 '2'와 최대한 유사하게 복원되는 것이 목표이다.
2) 이미지 복원
Figure 10: Face completion by filling in the missing pixels (source: SymmFCNet)
출처: https://pyimagesearch.com/
이미지의 구성:
왼쪽 열 (Input):
얼굴의 일부가 하얗게 지워진(누락된) 이미지이다.
첫 번째는 사각형 형태로, 두 번째는 불규칙한 형태로 픽셀 데이터가 유실된 상태이다.
오른쪽 열 (Output):
딥러닝 모델이 빈 공간의 내용을 예측하여 생성해낸 결과물이다.
눈, 코, 입의 위치와 피부 톤을 주변 맥락에 맞춰 자연스럽게 복원했다.
오토인코더: 작동 원리
특징 학습:
모델은 수만 장의 정상적인 얼굴 이미지를 학습하여 "사람의 얼굴은 대개 눈이 어디에 있고, 코와 입은 어떤 모양이다"라는 잠재적인 특징(Latent Features)을 미리 파악하고 있다.
맥락 파악 (Encoding):
왼쪽의 손상된 이미지가 입력되면, 인코더는 손상되지 않은 나머지 영역을 통해 이 인물이 어떤 표정을 짓고 있고 어떤 각도를 보고 있는지 분석한다.
이미지 생성 (Decoding):
디코더는 인코더가 파악한 정보를 바탕으로, 학습했던 "얼굴의 데이터 분포"를 활용해 빈칸에 가장 어울리는 픽셀 값들을 채워 넣는다.