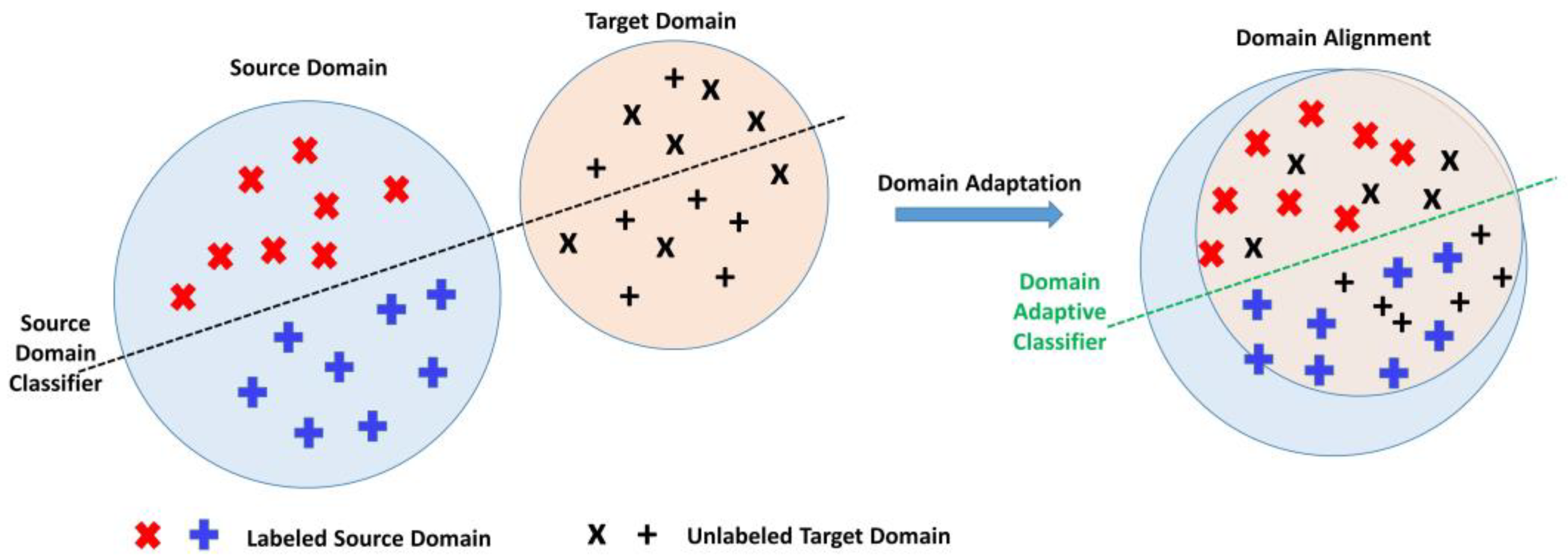
다음 그림은 Domain Adaptation의 개념 흐름을 시각적으로 설명한 예시이다.
출처: Scholarly Community Encyclopedia
🔗 관련 문서: Wikipedia - Domain Adaptation
Domain Adaptation은 소스 도메인(Source Domain)에서 학습된 모델이 타겟 도메인(Target Domain)에서도 높은 성능을 유지할 수 있도록 설계된 전이학습(Transfer Learning)의 한 형태이다.
두 도메인의 데이터 분포가 다르더라도, 특징을 정렬하거나 적대적 학습을 통해 성능 저하 없이 일반화를 달성하는 것이 목적이다.
Domain Adaptation은 소스 도메인에서 충분한 라벨을 가지고 학습한 모델이, 라벨이 없거나 적은 타겟 도메인에서의 성능을 향상시키기 위한 방법론이다.
주된 문제는 도메인 시프트(domain shift)로, 소스와 타겟 간의 데이터 분포 차이를 어떻게 좁히느냐가 핵심 과제이다.
장점
한계
다음 그림은 Domain Adaptation의 개념 흐름을 시각적으로 설명한 예시이다.

Contrastive Domain Adaptation (대조 도메인 적응, CDA)과 Adversarial Domain Adaptation (적대적 도메인 적응, ADA)은 모두 레이블이 풍부한 소스 도메인(\( D_S \))에서 학습한 모델을 레이블이 부족한 타겟 도메인(\( D_T \))에 일반화시키기 위해 도메인 이동(Domain Shift) 문제를 해결하는 딥러닝 기법이다.
두 방법은 도메인 간의 특징 분포를 맞추는(Alignment) 방식에서 근본적인 차이를 보인다다.
CDA는 대조 학습(Contrastive Learning, CL) 기법을 사용하여 특징 공간(Feature Space)을 조정함으로써 도메인 적응을 수행한다.
ADA는 적대적 학습(Adversarial Learning), 즉 GAN(Generative Adversarial Network)의 원리를 응용하여 도메인 적응을 수행한다.
| 구분 | Contrastive Domain Adaptation (CDA) | Adversarial Domain Adaptation (ADA) |
|---|---|---|
| 핵심 기법 | 대조 학습(Contrastive Learning) | 적대적 학습(Adversarial Training) |
| 메커니즘 | 특징 공간에서 클래스별 거리를 명시적으로 조절 | 도메인 판별자를 속여 도메인 불변 특징을 생성 |
| 주요 목표 | 식별력을 유지하면서 도메인 정렬 | 도메인 분포 자체의 유사성 최대화 |
| 주요 장점 | 클래스 정보 활용으로 정확한 정렬, 클러스터 경계 명확화 | 도메인 전체 분포를 맞추는 데 효과적, 구현 용이성 |
대조 학습(Contrastive Learning)의 핵심 개념
같은 클래스 또는 유사한 특성을 가진 데이터 쌍
이 그림에서:
학습 목표:
다른 클래스 또는 상이한 특성을 가진 데이터 쌍
이 그림에서:
학습/추론 목표:
핵심 원리
▸ Positive pair → 거리 최소화 (pull together)
▸ Negative pair → 거리 최대화 (push apart)
# Positive pair
loss_positive = ||f(source) - f(target)||² # 작을수록 좋음
# Negative pair
loss_negative = max(0, margin - ||f(normal) - f(abnormal)||²) # 클수록 좋음
1. 학습 단계 (Phase 2 상단)
2. 추론 단계 (Phase 2 하단)
| 구분 | Positive Pair | Negative Pair |
|---|---|---|
| 관계 | 같은 클래스 | 다른 클래스 |
| 예시 | 정상-정상 | 정상-비정상 |
| 목표 | 유사도 증가 | 유사도 감소 |
| 특징 공간 | 가깝게 배치 | 멀리 배치 |
| 학습 방향 | Pull together (당기기) | Push apart (밀어내기) |
💡 결론
이 프레임워크는 positive pair로 정상의 경계를 학습하고, negative pair(비정상)를 그 경계 밖에서 탐지하는 방식이다.
실제 비정상 데이터 없이도 정상 데이터만으로 이상 탐지가 가능한 효과적인 방법론이다.