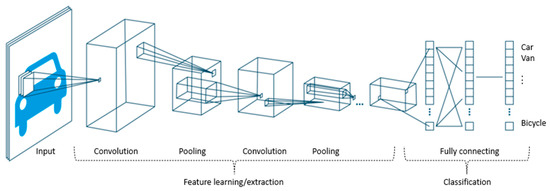
CNN (합성곱 신경망)은 이미지나 시계열 데이터 같은 격자형 데이터를 처리하는 데 특화된 딥러닝 모델이다. 특히 이미지 인식 분야에서 혁혁한 성과를 보였으며, 이미지에서 중요한 특징(Feature)을 자동으로 추출하고 학습한다.
CNN의 핵심 구성 요소는 합성곱 계층(Convolutional Layer)과 풀링 계층(Pooling Layer)이며, 이 과정을 통해 데이터의 크기를 효과적으로 줄이면서도 핵심 정보를 유지한다.
일반적인 CNN의 아키텍처(구조)는
(1) 합성곱,
(2) 활성화,
(3) 풀링 계층(레이어)을 반복하고
(4) 마지막에 완전 연결 계층을 사용한다.
출처: https://doi.org/10.3390/electronics12112402
전연결(FC, Fully Connected) 층(Layer)만으로 구성된 인공 신경망의 입력 데이터는 1차원(배열) 형태로 한정된다.
한 장의 컬러 사진은 3차원 데이터이다.
하지만 배치 모드에 사용되는 여러 장의 사진은 4차원 데이터이다.
사진 데이터로 전연결 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화시켜야 한다. 사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수밖에 없다. 결과적으로 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율적이고 정확도를 높이는데 한계가 있다. 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델이 바로 CNN이다.
출처: http://taewan.kim/post/cnn/
01. 1단계: 입력(4x4) 및 필터(2x2) 정의
CNN에 들어가는 입력 데이터는 픽셀 값으로 이루어진 행렬(Matrix)이다. 여기서는 \(4 \times 4\) 크기의 흑백 이미지를 사용하며, 픽셀 값은 0 또는 1로 단순화한다.
입력 이미지 (I)
\(4 \times 4\) 행렬.
필터 (F)
\(2 \times 2\) 행렬. 이 필터는 학습을 통해 결정되며, 이미지의 특정 패턴(예: 수평선, 대각선 등)을 감지하는 역할을 한다.
사용되는 하이퍼파라미터는 Stride(필터 이동 보폭) \(S=1\)과 Padding(경계 픽셀 추가 여부) \(P=0\)이다.
[Note] Stride와 Padding
시계열 데이터를 다룰 때 사용하는 Overlapping과 Zero Padding과 유사한 개념이다.
02. 2단계: 합성곱 연산 (Feature Extraction) (3x3)
합성곱(Convolution) 연산은 필터(F)를 입력 이미지(I) 위로 Stride 간격(\(S=1\))으로 이동시키면서, 겹치는 영역의 요소별 곱셈 후 총합을 구하는 과정이다. 이 연산을 통해 이미지의 특징을 추출한 특징 맵(Feature Map)을 생성한다.
합성곱은 필터가 이미지를 훑으며 특징을 추출하는 과정이다.
커널(kernel)을 슬라이딩(sliding, 한 칸씩 옮김)하며,
원소별 곱·합으로 특징 맵(feature map)을 생성
예: 좌상단 3×3 윈도우와의 원소별 곱의 합은 2가 된다.
합성곱 계산 절차
필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산한다. 여기서 지정된 간격으로 필터를 순회하는 간격을 Stride라고 한다.
출처: http://taewan.kim/post/cnn/
\(4 \times 4\) 입력에 \(2 \times 2\) 필터(\(S=1, P=0\))를 적용하면, 출력 크기는 \((4-2)/1 + 1 = 3\) 이므로 \(3 \times 3\) 특징 맵이 생성된다.