GRU는 은닉 상태와 (메모리) 셀 상태를 하나로 통합해 사용한다. 입력과 이전 상태를 바탕으로 두 개의 게이트가 정보 흐름을 조절하고, 새로운 은닉 상태를 생성한다. 이 덕분에 LSTM보다 학습 속도가 빠르며, 장기 의존성도 어느 정도 유지 가능하다.
다음의 2개의 게이트로 구성된다.
Update Gate:
이전 상태의 정보를 얼마나 유지할지 결정
Reset Gate:
과거 정보를 얼마나 잊을지 조절
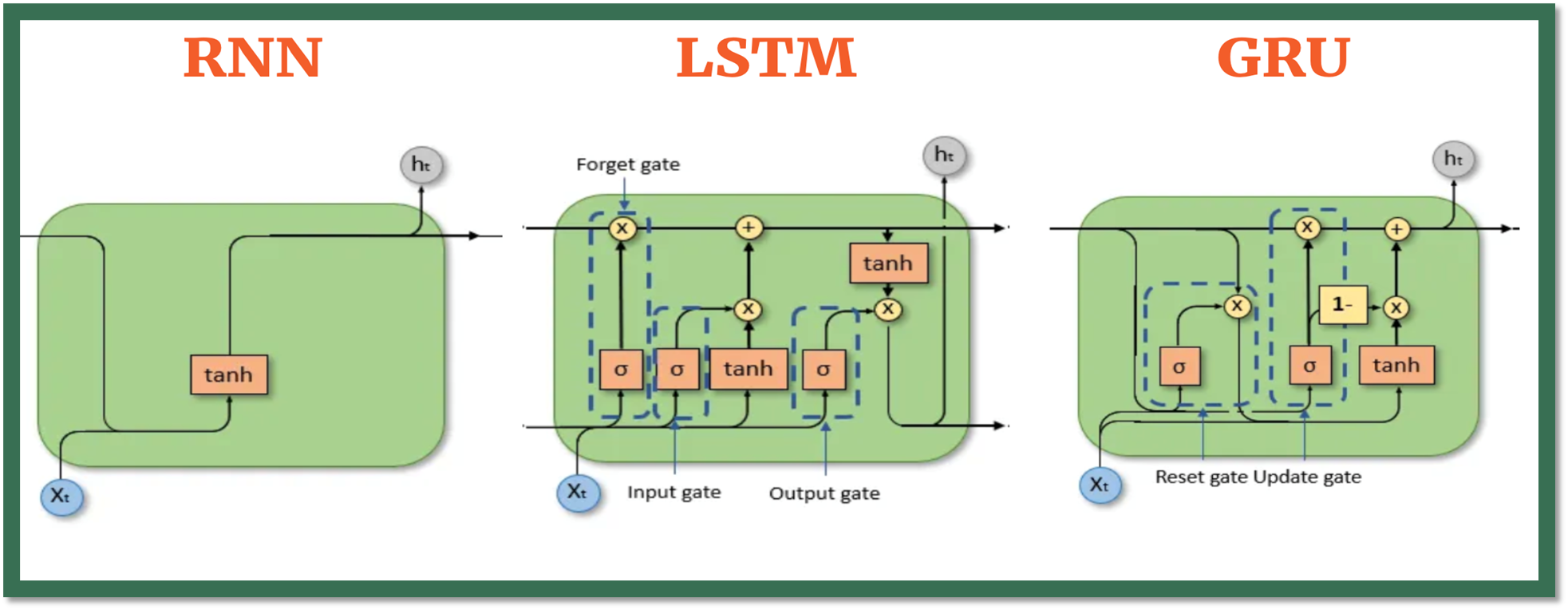
출처: https://python.plainenglish.io/introducing-gru-rnn-and-lstm-a-beginners-guide-to-understanding-these-revolutionary-deep-35b509a34a5a

출처: https://doi.org/10.17977/um018v6i22023p215-250

출처: https://doi.org/10.48550/arXiv.2007.12269