우주의 모든 것에는 패턴이 있다.
출처: https://jalammar.github.io/illustrated-word2vec/
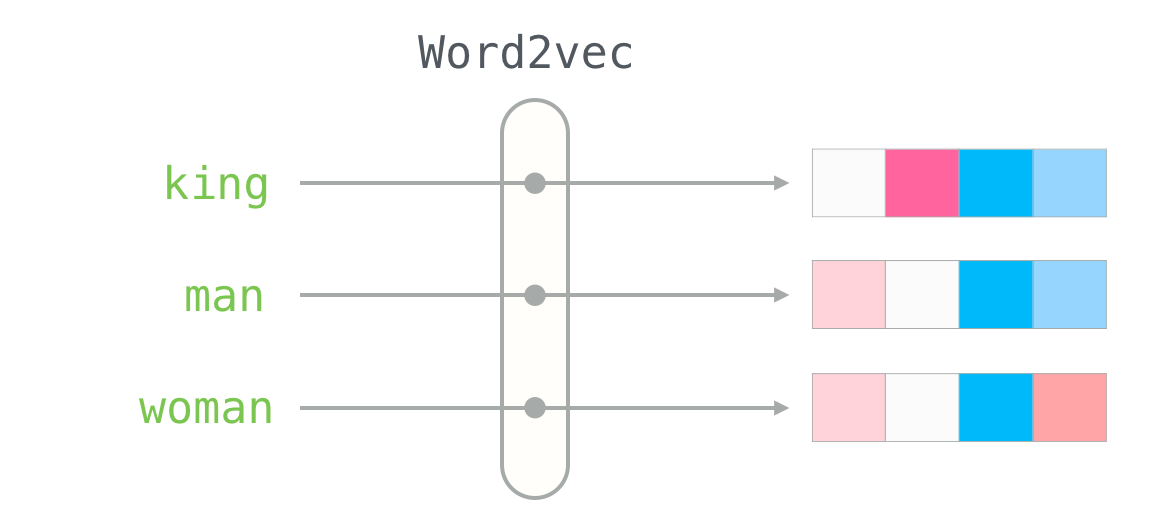
임베딩은 텍스트, 이미지 등 비정형 데이터를 컴퓨터가 이해할 수 있는 수치적 벡터로 변환하는 과정 또는 그 결과물이다.
임베딩은 고차원 데이터를 저차원 공간의 벡터로 표현함으로써 데이터의 의미적 유사성을 측정할 수 있도록 하며, 인공지능 모델이 단어나 이미지 등 객체 간의 관계를 이해하고 처리하는 데 핵심적인 역할을 담당한다.

여러분은 서울과 부산 중 대전과 더 가까운 곳은 어디일까? 정답을 알기 위해서는 무엇이 필요할까? 지도를 펼쳐 보거나 숫자로 표현된 위도와 경도를 알아보면 된다. (사실 대전은 부산보다 서울과 더 가깝다.)
이것이 바로 임베딩의 원리이다. 지도에서 위치를 숫자로 나타내는 것처럼 단어들도 숫자로 변환해서 관계를 배치하는 것이 임베딩이다. 임베딩(embedding)이란 단어나 문장을 숫자로 변환한 후 벡터 공간에 배치하는 과정이다. 즉, 단어를 벡터로 바꾸어 ‘좌표(위치)’를 부여하는 과정이다. 앞에서 살펴본 것처럼 서울, 도쿄, 뉴욕 같은 도시를 지도에 배치하면 서로의 거리와 관계를 알 수 있다. 마찬가지로 단어들도 올바른 위치(벡터 공간)에 배치해야 서로 의미를 파악할 수 있다.
이렇게 임베딩을 하는 목표는 간단하다. 바로 단어 간 관계를 숫자로 계산하기 위함이다. 인공지능이 답변을 할 때는 서로 관련된 단어들을 조합해서 답변해야 한다. 그렇게 하려면 어떤 단어들이 관련이 있는지, 또 어떤 단어들이 관련 없는지를 계산해야 한다. 이렇게 계산을 할 수 있도록 특정한 공간에 단어를 위치시키는 과정이 바로 임베딩 과정이다.
이제 우리가 얻은 토큰 ID를 통해 살펴보자.
[40, 1097, 21630, 4037, 2065, 13]
이 숫자들은 단어를 고유한 숫자로 변환한 값일 뿐이다. 즉, 이 숫자들만으로는 단어 의미를 비교할 수 없다.
그런데 이 숫자들이 의미를 가지려면 어떻게 해야 할까? 바로 숫자 하나하나(각각의 토큰 ID)를 의미 있는 좌표로 변환해야 한다. 이 과정이 바로 임베딩입니다. 실제로 임베딩을 할 때는 512차원 이상의 고차원 벡터로 변환한다. 하지만 쉽게 이해하기 위해 2차원으로 임베딩해 보자.
예를 들어 각 토큰이 다음과 같은 2차원 벡터로 임베딩되어 있다고 생각해 보자.
| 토큰 | 토큰 ID | 초기 임베딩 벡터 |
|---|---|---|
| I | 40 | [3, 4] |
| am | 1097 | [10, 15] |
| study | 21630 | [5, 9] |
| ... | ... | ... |
이 모습을 이해하기 쉽게 좌표 평면으로 나타내어 보자.
그림 1. 학습 전 2차원 벡터로 임베딩
이처럼 모델이 학습되기 전에는 ‘I’와 ‘am’의 임베딩은 무작위(initialized randomly) 또는 사전 학습(pre-trained)이 안 된 상태일 수 있으므로, 의미와 관계없이 멀리 떨어져 있을 수 있다.
하지만 모델이 문맥(context) 정보를 학습하게 되면 ‘I am’, ‘You are’, ‘He is’ 등의 패턴을 반복적으로 접한다. 이러한 반복을 통해 ‘I’ 다음에 ‘am’이 자주 등장한다는 것을 학습하게 되고, 이를 바탕으로 임베딩 벡터도 조정된다.
| 토큰 | 토큰 ID | 학습 이후 임베딩 벡터 |
|---|---|---|
| I | 40 | [4, 5] |
| am | 1097 | [6, 4] |
| ... | ... | ... |
다음 그림과 같이 조정된다.
그림 2. 학습 후 조정된 임베딩
이렇게 모델이 학습된 ‘I’라는 문자를 생성하면, I와 비슷한 위치에 있는 ‘am’이라는 단어가 생성될 확률이 높아진다. 이것이 바로 생성형 인공지능의 원리이다.
그렇기 때문에 우리가 앞으로 살펴볼 내용은 인공지능 모델이 이 벡터값들을 어떻게 변화시키면서 학습하는가이다.