Gemini는 Google DeepMind가 개발한 멀티모달 대형 언어 모델(LLM)이다.
텍스트, 이미지, 오디오, 비디오, 코드 등 다양한 입력을 동시에 처리할 수 있으며, 최신 버전은 깊은 추론(Thinking)과 자율적 행동(Agentic) 능력을 갖춘 차세대 AI 에이전트로 진화하였다.
(1) Gemini 버전 역사
Gemini는 1.0 시리즈를 시작으로 지속적으로 성능과 효율성을 개선해오고 있다.
Gemini 1.0 / 1.5 (2023 ~ 2024): 멀티모달의 시작 및 1M~2M 토큰의 긴 컨텍스트 창(Context Window) 도입.
Gemini 2.0 (2025.02): 속도와 효율성이 대폭 향상된 차세대 표준 모델(Flash/Pro).
Gemini 2.5 (2025.06): 고도화된 추론(Advanced Reasoning) 능력과 코딩 성능 강화.
Gemini 3.0 Preview (2025.11): 최신 실험적 모델로, 더욱 강력한 에이전트 기능과 복합적인 문제 해결 능력 탑재.
(2) 주요 기능
네이티브 멀티모달(Native Multimodal): 학습 단계부터 텍스트, 이미지, 영상, 음성을 동시에 학습하여 별도의 모듈 없이 모든 감각을 이해하고 생성.
에이전트 & 추론(Thinking): 복잡한 과제를 스스로 계획하고 단계를 나누어 해결하는 사고(Thinking) 모델 탑재.
초장문 문맥 처리(Long Context): 최대 200만(2M) 토큰 이상을 처리하여 책 수백 권 분량이나 긴 영상을 한 번에 분석 가능.
온디바이스 AI (Nano/Banana): 인터넷 연결 없이 기기 자체에서 이미지 생성 및 실시간 처리가 가능한 경량화 모델 제공(Gemini Nano Banana Pro 등).
(3) 타 모델과 비교
모델
주요 특징
멀티모달
컨텍스트 창
Gemini (3.0/2.5)
네이티브 멀티모달 + 에이전트 추론
O (영상/음성 최적화)
최대 2M+ (가장 큼)
GPT-4o / o1
고성능 논리 추론 및 대화
O
128k
Claude 3.5
자연스러운 문장력 + 코딩 능력
O (이미지 중심)
200k ~ 500k
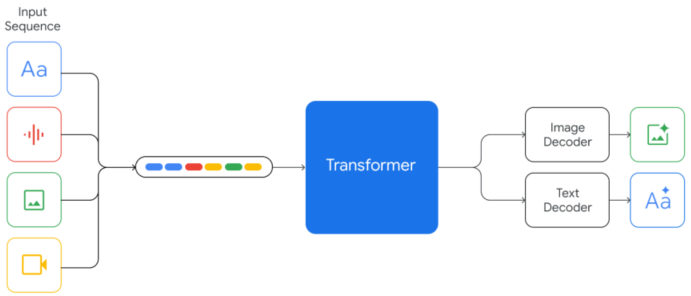
(4) 구조 개념도
Gemini는 텍스트와 비전, 오디오를 각각 별도로 처리하지 않고 하나의 모델 안에서 통합 처리하는 MoE(Mixture-of-Experts) 기반의 아키텍처를 사용한다.