[Home] AI로 돌아가기
🔗 관련 문서:
Wikipedia - Knowledge Distillation
|
논문: Distilling the Knowledge in a Neural Network
Knowledge Distillation - 지식 증류
Knowledge Distillation은 대규모 AI 모델(Teacher)이 학습한 지식을
소형 모델(Student)에 압축 및 전이하는 기술이다.
이를 통해 경량 모델도 높은 성능을 낼 수 있으며, 실시간 추론에 매우 적합하다.
(1) 지식 증류란?
지식 증류(Knowledge Distillation)은 Teacher 모델이 학습한
Soft Target 정보를 활용하여 Student 모델을 훈련시키는 기법이다.
즉, 복잡한 지식을 간결하게 전이하는 것이 핵심이다.
(2) 지식 증류 과정
- Teacher 학습: 대규모 모델이 데이터 학습
- Soft Target 생성: 정답뿐 아니라 다른 클래스의 분포 정보도 제공
- Student 학습: Soft Target 기반 학습으로 일반화 향상
(3) 지식 증류의 장점
- 모델 경량화: 파라미터 수를 대폭 축소 가능
- 실행 효율: 추론 속도 향상, 메모리 및 배터리 절약
- 하드웨어 호환성: 모바일·IoT 환경에서 고성능 모델 사용 가능
(4) 지식 증류의 활용
- NLP: 번역기, 요약기, 챗봇 등에 대형 LLM의 성능을 경량 모델에 이식
- Computer Vision: 이미지 분류 및 탐지 모델의 최적화
- 음성 인식: ASR 모델을 모바일 환경으로 축소 적용
(5) 개념도
지식 증류는 다음과 같은 구조로 이루어진다:
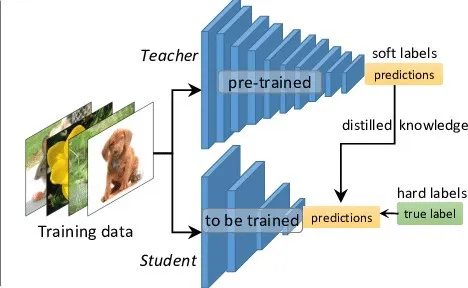 그림 1. Teacher → Student로의 지식 전이 과정
그림 1. Teacher → Student로의 지식 전이 과정
출처: Medium - Knowledge Distillation in NLP