[Home] AI로 돌아가기
🔗 관련 문서:
Wikipedia - Mixture of Experts
MOE (Mixture of Experts) - 전문가 조합
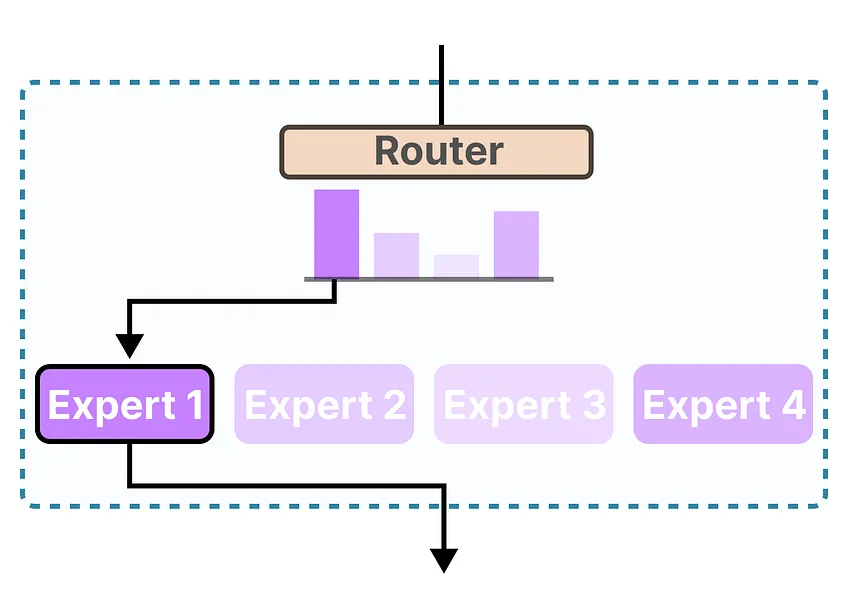
MOE는 다양한 전문가 네트워크(Experts)를 조합하여,
입력에 따라 가장 적합한 전문가만 선택적으로 활성화하는 구조이다.
이는 대규모 딥러닝 모델의 효율성과 확장성을 극대화하기 위한 아키텍처이다.
(1) MOE의 핵심 요소
- 전문가 네트워크(Experts): 독립적인 모델 모듈 집합.
예: 문법 분석 전문가, 문맥 이해 전문가 등
- 게이트웨이 네트워크(Gating Network): 입력에 따라 어떤 전문가를 선택할지 결정
- 부분 활성화(Sparse Activation): 전체 전문가 중 일부만 활성화하여 연산량 감소
(2) MOE의 작동 방식
- 입력 데이터 수신
- 게이트웨이 네트워크가 전문가 선택
- 선택된 전문가만 활성화되어 작업 수행
- 출력 결과를 조합하여 최종 결과 생성
(3) MOE의 장점
- 성능 향상: 선택적 활성화로 연산 효율 증가
- 확장성: 전문가를 추가하면서도 비용은 선형 증가
- 리소스 절약: GPU/TPU 사용 효율화
(4) MOE의 활용 사례
- 대규모 언어 모델: GPT-4, PaLM, GShard 등
- 자연어 처리: 번역, 질의응답, 문맥 분석 등
- 추천 시스템: 사용자별 맞춤 전문가 활성화
- 컴퓨터 비전: 영상 인식에서 전문가 병렬 사용
(5) 개념도
MOE는 입력에 따라 선택적으로 전문가를 활용하는 아키텍처로, 다음과 같이 구성된다:
 A Visual Guide to Mixture of Experts (MoE)
A Visual Guide to Mixture of Experts (MoE)
출처: https://newsletter.maartengrootendorst.com/