[Home] AI로 돌아가기
🔗 관련 문서:
Wikipedia - Model Compression
Model Compression - 모델 소형화
모델 소형화(Model Compression)는 대규모 인공지능 모델의 연산 비용을 줄이고,
적은 자원으로도 실행 가능하도록 만드는 기술이다. 이는 엣지 디바이스, 모바일 환경에서 특히 중요하다.
(1) 모델 소형화의 필요성
- 대형 언어 모델(LLM)은 자원 소모가 매우 큼
- 스마트폰, IoT 기기 등에서 실행 가능하도록 최적화 필요
- 인간의 뇌는 24W의 에너지만 소비 – AI도 효율성을 따라가야 함
(2) 모델 소형화 방법
- 모델 경량화: 네트워크 구조 단순화
- 양자화(Quantization): 32비트 → 8비트로 가중치 변환
- 프루닝(Pruning): 중요하지 않은 뉴런 및 가중치 제거
- 가중치 공유(Weight Sharing): 같은 가중치 재사용
- 지식 증류(Knowledge Distillation): 대형 모델 → 소형 모델로 지식 이전
- NAS: Neural Architecture Search로 최적 구조 탐색
- 데이터 압축 및 샘플링: 효율적인 학습 데이터 구성
- 하드웨어 최적화: GPU, TPU 등에서 병렬 최적화
(3) 활용 사례
- 모바일 애플리케이션: AI 비서, 번역기 등
- 엣지 컴퓨팅: IoT 및 스마트 디바이스
- 의료기기: 경량화된 AI 진단
- 인터넷 제한 지역: 오프라인 AI 서비스 가능
(4) 개념도
다양한 소형화 기법은 다음과 같이 전체적인 모델 최적화에 기여한다:
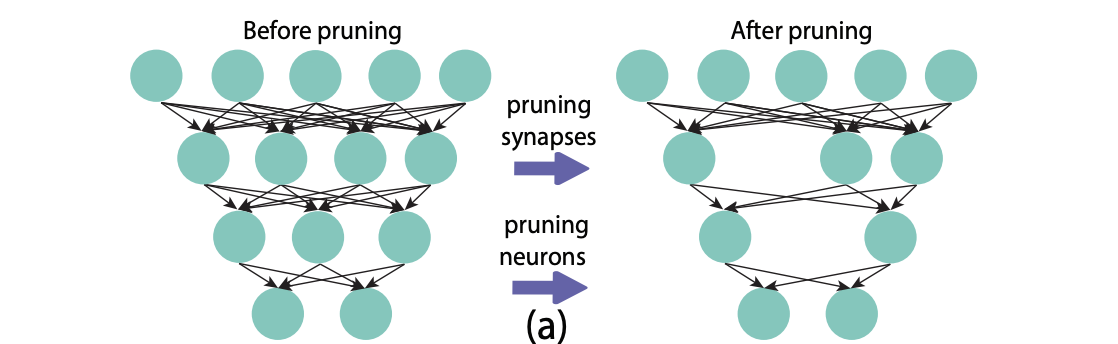 그림 1. 다양한 모델 압축 기법과 구조
그림 1. 다양한 모델 압축 기법과 구조
출처: Medium - Model Compression Overview