출처: Wikimedia Commons
🔗 관련 문서: Wikipedia - Support Vector Machine
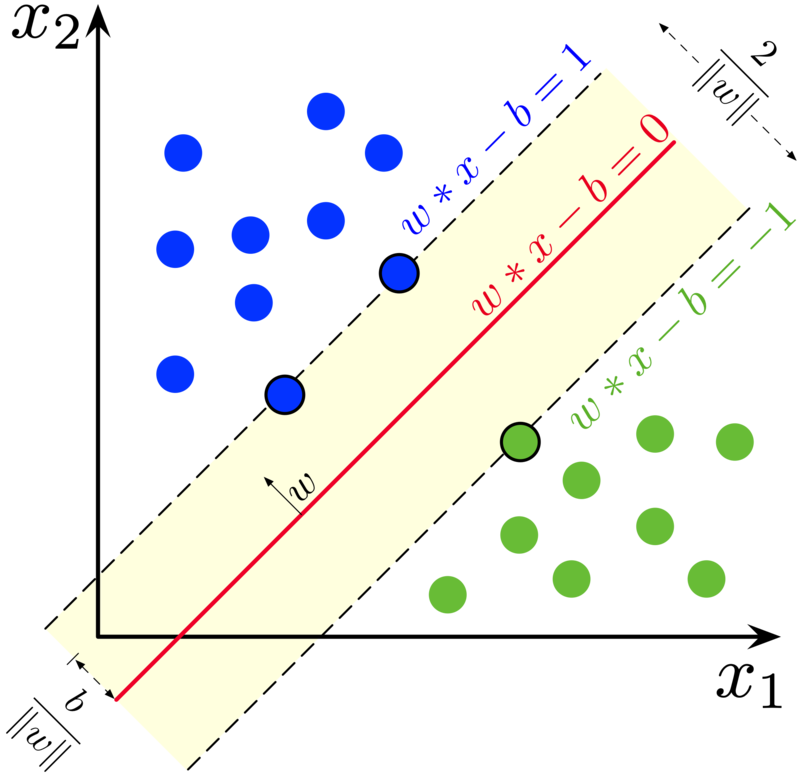
SVM은 지도 학습(Supervised Learning) 방식의 분류(Classification) 및 회귀(Regression) 알고리즘으로, 주어진 데이터를 가장 잘 구분하는 초평면(hyperplane)을 찾아내는 것을 목표로 한다.
두 클래스 사이의 마진(margin)을 최대화함으로써 일반화 성능을 높이는 것이 SVM의 핵심 원리이다.
Support Vector Machine은 데이터를 구분하는 선형 또는 비선형의 결정 경계를 설정하며, 가장 가까운 샘플들(Support Vectors)로부터 최적의 분리 초평면을 계산한다.
마진이 넓을수록 새로운 데이터에 대해 더 나은 일반화 성능을 기대할 수 있다. 선형으로 구분되지 않는 경우에는 커널 함수(Kernel Function)를 통해 고차원 공간으로 데이터를 사상시켜 분리가 가능하도록 한다.
장점
한계
다음은 SVM의 결정 경계와 서포트 벡터를 시각적으로 나타낸 예시이다.
한반도의 DMZ는 38선에서 ±5 km이다.
