왜 트랜스포머(Transformer)란 이름을 사용하였을까?
이 모델의 주요 목적이 입력 시퀀스를 출력 시퀀스로 변환하는 것이었다. 특히 기계 번역에서 영어 문장 → 독일어 문장으로 변환하는 작업을 수행하기 때문에 "변환기(transformer)"라는 의미가 적합했다.
트랜스포머(Transformer)는 2017년 구글 연구팀이 발표한 논문 "Attention is All You Need"에서 처음 소개된 딥러닝 모델 구조이다.
이전까지 자연어 처리 분야를 지배하던 순환신경망(RNN)과 장단기 메모리(LSTM)의
한계를 극복하기 위해 개발되었다.
현재 모든 인공지능 모델에서 사용되는 기본 모델이다.
\(d_{model}\): 출력 차원 (embedding vector 차원)
\(pos\): 입력 시퀀스 데이터에서의 embedding vector 위치
(예: 나는 = 0, 학생 = 1, 이다 = 2)
\(i\): embedding vector 내 차원의 순서 (예: 4차원일 때 0, 1, 2, 3)
출처: https://youtu.be/a_-YgMO0u0E
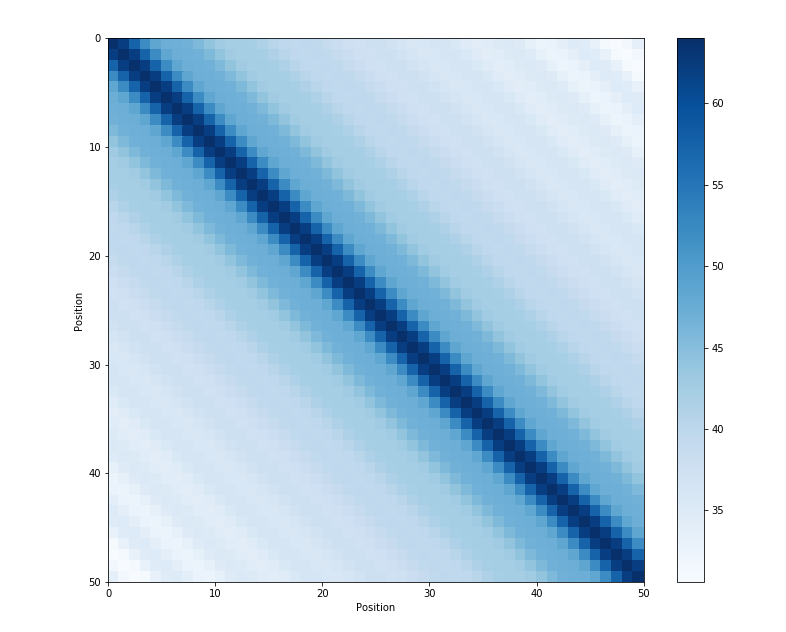
위치 인코딩(Sinusoidal position encoding) 특징
가까운 위치의 단어끼리는 유사도가 크다.
먼 위치의 단어끼리는 유사도가 작다.
모든 타임스텝에 대한 위치 임베딩의 내적(Dot product)
출처: https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
03. 트랜스포머의 구조
3.0 개요
트랜스포머는 크게 인코더(Encoder)와 디코더(Decoder)라는 2개의 주요 블록으로 구성된다. 각각은 여러 개의 동일한 층(layer)이 쌓여 있는 구조이다.
겉으로 보면 기존의 Seq2Seq(인코더-디코더) 구조와 비슷해 보이지만, 내부에서는 RNN 없이도 더 유연하고 강력하게 문장을 처리할 수 있는 비밀이 숨어 있다.
Transformer는 Encoders-Decoders 구조로 구성된다.
실제 Encoders와 Decoders는 다음과 같다.
N개의 모듈(Encoder)로 구성되며, 각 모듈의 구조는 동일
각 모듈(Encoder)의 파라미터는 다름
이전 모듈의 output이 다음 모듈의 input이 됨 (단, 맨 처음은 입력값)
출처: https://jalammar.github.io/illustrated-transformer/
Transformer는 Encoder-Decoder로 구성 •
각 N개의 모듈로 구성되며, 각 모듈의 구조는 동일하다.
Encoder-Decoder에 입력되는 Q는 Decoder에서, K와 V는 Encoder에서 온 벡터들이다.
디코더(Decoder)의 Query 벡터 \(Q\)와 인코더(Incoder)의 Key 벡터 \(K\)를 비교하여
Attention Score를 계산하고,
인코더(Incoder)의 Value 벡터 \(V\)를 곱하여
최종적으로 입력과 차원이 같은 특징 벡터 \(Z\)를 도출한다.
(예: Decoder의 "am"과 Incoder의 "나는 학생 이다"와의 관계를 나타낸다)
(즉, "am"은 "이다"에 가장 큰 Attention Score를 갖는다)
수정 Value 벡터 \( v_1' \)= \( \text{softmax} \left(\frac{q_1 \cdot k_1}{\sqrt{d_k}}\right) \times \) Value 벡터(1x2) \(v_1\)
특징 벡터(1x2) \(z_1 \) = 수정 Value 벡터의 합 \( \sum{v'_i}\)
4.3 멀티-헤드 어텐션(Multi-Head Attention)
트랜스포머는 하나의 어텐션만 사용하는 것이 아니라, 여러 개의 어텐션을 병렬로 수행하는 멀티-헤드 어텐션을 사용한다.
이를 통해 다양한 관점에서 문맥을 파악할 수 있다.
예를 들어, 8개의 헤드를 사용한다면 각 헤드에서부터 서로 다른 측면(문법적 관계, 의미적 유사성, 위치 관계 등)을 학습할 수 있다.
싱글-헤드 어텐션 (Single-Head Attention) 예시 Encoder에서 "it"이라는 단어를 Encoding하는 동안,
주홍색 Attention 헤드에서 일부는 "The Animal"에 집중했고,
그 표현의 일부를 "it"의 Encoding에 포함시켰다.
(출처: https://jalammar.github.io/illustrated-transformer/)
멜티-헤드 어텐션 (Single-Head Attention) 예시 멀티-헤드 어텐션은 여러 개의 머리를 가진 괴물(The Beast With Many Heads, 말하자면, 여러 생각을 갖는 ADHD)이다.
2개-헤드 Encoder에서 "it"이라는 단어를 Encoding하는 동안,
첫 번째 주홍색의 Attention-Head는 "The Animal"에 집중했고,
두 번째 녹색의 Attention-Head는 "tire"에 집중했다.
즉, 이 모델은 "it"이라는 단어를 표현하는 방식에는
"The Animal"과 "tire"라는 두 가지 의미의 표현이 모두 포함되었다.
(출처: https://jalammar.github.io/illustrated-transformer/)
"나는 학생 이다"에 해당하는 최종 특징 벡터(\(Z\))를 구하는 과정 최종 특징 벡터(\(Z\)) = Self-Attention Score 벡터(\(S\)) \( \times \) Value 벡터(\(V\))
(출처: https://youtu.be/a_-YgMO0u0E)
싱글-헤드에서 Q-K-V에 대해 멀티 필터(가중치 행렬)를 사용하여 멀티-헤드로 확장하는 과정 CNN에서는 서로 다른 필터 사용
(출처: https://youtu.be/a_-YgMO0u0E)
멀티-헤드 어텐션 (Multi-Head Attention) 과정 요약
자연어 문장인 "Thinking Machines"을 입력
워드 임베딩 + 위치 인코딩 → Embedding 벡터(2x4) \(X\)
8개의 멀티-헤드를 사용한 8개 Q/K/V Encoder 벡터(2x3) \(Q, K, V \)생성
\(Q_0 = X W_0^Q = X \times \) Query 벡터(4x3) \( W_0^Q \)
\( \cdots \)
\(Q_7 = X W_7^Q = X \times \) Query 벡터(4x3) \( W_7^Q \)
문장을 한 단어씩, 미리 보지 않고 추측하는 방법을 누군가에게 가르친다고 가정해 보자. 세 번째 단어를 예측할 때는 첫 번째와 두 번째 단어만 볼 수 있고, 앞으로 나올 단어(네 번째, 다섯 번째…)는 볼 수 없다.
이것을 마스킹(Masking)이라고 한다.
미래를 숨기거나 차단하는 것이다.
이렇게 하면 모델이 미래를 미리 보는 부정행위를 하는 것을 방지할 수 있다.
{Q} 미래 시점에 대해 마스킹하는 이유는?
모델은 순차에서 선행하는 단어에만 중요도를 부여하여, 이전 예측 단어를 기반으로 올바른 예측 단어를 생성하도록 학습하기 위함이다.
디코더(Decoder): 마스크드 셀프 어텐션(Masked Self-Attention)
디코더에서는 "I am a student"라는 영문에 대해 Self-Attention을 한다.
워드 임베딩 + 위치 인코딩 → Embedding 벡터(2x4) \(X\)
Masked란 미래 시점 정보는 활용할 수 없도록 제약(-∞)을 부여한다.
즉, Attention Score가 0이 되도록 한다.
(예: "I" 시점에서는 "am a student"를 볼 수는 없다)
(예: "am" 시점에서는 "I am"만 볼 수 있고, "a student"는 볼 수는 없다)
현시점의 Query 벡터 \(Q\)와 과거 시점의 Key 벡터 \(K\)를 비교하여
Attention Score를 계산하고,
최종적으로 입력과 차원이 같은 특징 벡터 \(Z\)를 도출한다.
트랜스포머는 자연어 처리 분야에서 혁명적인 성과를 가져왔으며, 현재 다양한 분야에서 활용되고 있다.
(1) 자연어 처리
기계 번역 Google Translate 등에서 높은 번역 품질을 제공한다.
텍스트 생성 GPT 시리즈처럼 자연스러운 문장을 생성한다.
질의응답 문맥을 이해하여 정확한 답변을 제공한다.
감정 분석 텍스트의 감정과 의도를 파악한다.
요약 긴 문서를 핵심 내용으로 압축한다.
(2) 컴퓨터 비전
Vision Transformer(ViT)는 이미지를 패치로 나누어 트랜스포머에 입력함으로써, 기존 CNN 방식을 능가하는 성능을 보여주었다.
(3) 멀티모달
텍스트, 이미지, 음성 등 여러 형태의 데이터를 동시에 처리하는 멀티모달 모델에서도 트랜스포머가 활용된다. CLIP, DALL-E 등이 대표적인 예이다.
6.2 변형 모델들
트랜스포머 구조를 기반으로 다양한 변형 모델들이 개발되었다.
(1) BERT(Bidirectional Encoder Representations from Transformers)
구글이 개발한 모델로, 트랜스포머의 인코더만 사용한다. 양방향으로 문맥을 이해하여 텍스트의 깊은 의미를 파악한다. 문장의 빈칸 채우기(Masked Language Model) 방식으로 사전학습된다.
(2) GPT(Generative Pre-trained Transformer)
OpenAI가 개발한 모델로, 트랜스포머의 디코더만 사용한다. 이전 단어들을 바탕으로 다음 단어를 예측하는 방식으로 학습되며, 뛰어난 텍스트 생성 능력을 보인다. GPT-3, GPT-4 등으로 발전했다.
(3) T5(Text-to-Text Transfer Transformer)
모든 NLP 작업을 텍스트-투-텍스트 문제로 통일한 모델이다. 번역, 요약, 분류 등 모든 작업을 동일한 형식으로 처리한다.
(4) 기타 변형 모델
RoBERTa: BERT의 학습 방법을 개선한 모델
ALBERT: 파라미터 수를 줄여 효율성을 높인 모델
ELECTRA: 판별 모델을 활용한 효율적인 사전학습 방법
XLNet: 순열 언어 모델링을 도입한 모델
07. 트랜스포머의 핵심 요약
RNN 기반 방법론
→ 입력값을 순차적으로 전달받음
순차적으로 전달받은 정보를 통해 데이터가 지닌 시계열정보 반영이 가능
다만, 병렬처리에 어려움이 있으며 이는 연산측면에서 비효율적
Transformer → 입력값을 순차적으로 받는 것이 아닌 한번에 입력을 수행
병렬처리가 가능하므로 연산측면에서 효과적으로 활용가능
Positional encoding 적용하여 시계열성 특징을 반영할 수 있음
(Self) Attention 구조를 통해 중요 시점정보(단어정보)를 반영할 수 있음
Transformer를 구성하는 다양한 모듈을 변경하여 다양한 문제상황에 적용
NLP machine translation, text summarization, question answering
Image image recognition, object detection
Manufacturing state classification, anomaly detection
트랜스포머는 현대 인공지능의 핵심 구조로 자리잡았으며,
ChatGPT, Claude, Gemini 등 최신 언어 모델들의 기반이 되고 있다.
RNN의 한계를 극복하고 Attention 메커니즘만으로 강력한 성능을 달성함으로써,
자연어 처리와 인공지능 분야의 패러다임을 완전히 바꾸어 놓았다.