[Home] AI로 돌아가기
🔗 관련 문서:
Wikipedia - Vector Quantization
벡터 양자화 (Vector Quantization)
벡터 양자화는 고차원의 연속적인 벡터 공간을 제한된 개수의 대표 벡터들로 근사하는 양자화 기법으로, 주로 데이터 압축 및 패턴 인식에 활용된다.
(1) 정의와 핵심 개념
벡터 양자화는 원본 벡터를 가장 가까운 대표 벡터(코드북의 벡터)로 치환하는 방식으로, 복잡한 데이터를 간단한 코드로 표현하는 기술이다.
이 때 사용되는 대표 벡터들의 집합을 코드북(Codebook)이라고 하며, 각 벡터는 하나의 클러스터 중심 역할을 한다.
(2) 알고리즘 원리
- 입력 데이터를 여러 개의 벡터(예: 이미지의 블록)로 나눈다.
- K-means 알고리즘 또는 유사한 방식으로 대표 벡터 집합(코드북)을 학습한다.
- 각 입력 벡터를 코드북 내 가장 가까운 벡터로 매핑하여 인덱스로 치환한다.
- 압축된 표현은 인덱스들의 집합으로 구성되며, 복원 시에는 해당 인덱스에 대응되는 코드북 벡터로 다시 변환된다.
(3) 장점과 한계
장점
- 압축 효율이 높아 저장 공간을 줄일 수 있다.
- 계산량 감소로 실시간 처리에 유리하다.
- 패턴 인식과 음성 인식, 영상 처리 등 다양한 분야에 응용 가능하다.
한계
- 정보 손실이 발생할 수 있다.
- 코드북 설계가 품질에 크게 영향을 준다.
- 코드북 학습에 시간이 소요될 수 있다.
(4) 개념도
다음은 벡터 양자화의 데이터 압축 개념을 나타낸 시각적 예시이다.
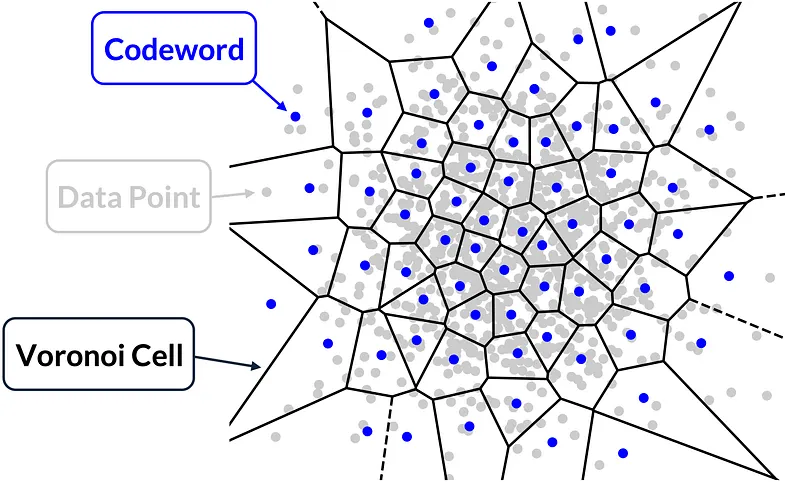 Vector Quantization Operation
Vector Quantization Operation
출처: https://medium.com/data-science