
출처: 길벗
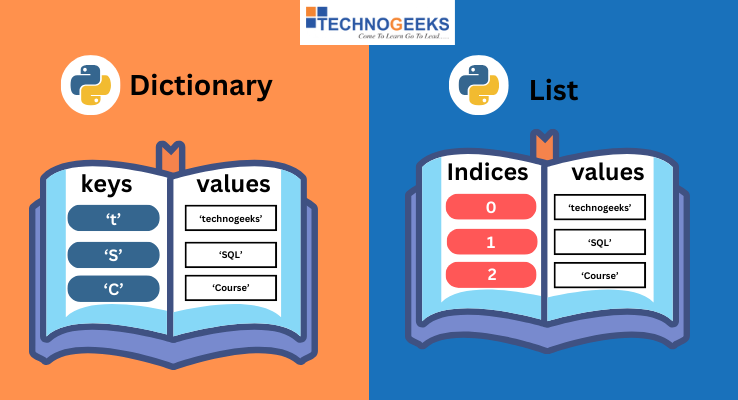
딕셔너리(dict)는 키(key)와
값(value)의 쌍을 저장하는 자료구조이다. 인덱스(0, 1, 2…) 대신
이름표를 붙여 꺼내는 주머니라고 생각하면 이해가 쉽다.
# 한 학생의 정보를 저장하는 딕셔너리
people = {
"name": "영웅",
"age": 25,
"hobby": "노래",
}
print(people["name"])
print(people["hobby"])
영웅
노래
리스트(list)는 순서로 값을 기억하고, 딕셔너리는 이름표(키)로
값을 찾는다. 예를 들어 사람의 나이를 꺼낼 때, 리스트라면 “두 번째” 위치를 기억해야 하지만
딕셔너리는 "age"라는 키만 알면 된다.
주의 · 따옴표 없이people[name]처럼 쓰면 파이썬은name을 변수로 인식한다. 키 문자열은 항상 따옴표로 감싸people["name"]처럼 사용한다.
# 존재하지 않는 키를 조회하면 KeyError가 발생
print(people["height"])
KeyError: 'height'
실무에서 LLM이 반환한 결과를 구조화하기 위해 딕셔너리(또는 JSON)를 자주 활용한다.
# LLM이 생성했다고 가정한 응답을 딕셔너리로 저장
result = {"generated_text": "안녕하세요! 무엇을 도와드릴까요?"}
print(result["generated_text"])
안녕하세요! 무엇을 도와드릴까요?
리스트 컴프리헨션(list comprehension; 리스트 내포함수)은 “값을 하나씩 꺼내 계산 → 결과를 모아 새로운 리스트로” 과정을 짧게 표현하는 문법이다.
# 기존 방식 (반복문 + append)
numbers = [1, 2, 3, 4, 5]
double_numbers = []
for num in numbers:
double_numbers.append(num * 2)
print(double_numbers) # [2, 4, 6, 8, 10]
# 리스트 컴프리헨션
result = [x * 2 for x in numbers]
print(result) # [2, 4, 6, 8, 10]
names = ["영웅", "소희", "보검"]
labels = ["보고 싶은 " + name for name in names]
print(labels)
# ['보고 싶은 영웅', '보고 싶은 소희', '보고 싶은 보검']
# 짝수만 2배
evens_times_two = [x * 2 for x in range(1, 11) if x % 2 == 0]
print(evens_times_two) # [4, 8, 12, 16, 20]
# 조건부 표현식(if-else)도 가능
tags = ["even" if x % 2 == 0 else "odd" for x in range(1, 6)]
print(tags) # ['odd', 'even', 'odd', 'even', 'odd']
람다(lambda)는 이름 없이(또는 이름 대신에) 짧게 정의하는 함수이다.
보통 한 줄 계산이나 정렬/매핑의 key 인자로 사용한다.
# 일반 함수
def square(x):
return x * x
# 같은 일을 하는 람다
square2 = lambda x: x * x
print(square(3), square2(3)) # 9 9
# 정렬 key에 사용
words = ["python", "ai", "gen"]
print(sorted(words, key=lambda w: len(w)))
# ['ai', 'gen', 'python']
[Note]
람다는 간결하지만 복잡한 로직에는 적합하지 않다. 가독성이 우선인 경우에는def로 함수를 정의한다.
map(func, iterable)은
모든 요소에 함수를 적용해 변환하고,
filter(func, iterable)은
조건에 맞는 요소만 남긴다.
최종적으로 리스트가 필요하면 list()로 감싼다.
numbers = [1, 2, 3, 4, 5]
# map: 모든 요소 2배
mapped = list(map(lambda x: x * 2, numbers))
print(mapped) # [2, 4, 6, 8, 10]
# filter: 짝수만
filtered = list(filter(lambda x: x % 2 == 0, numbers))
print(filtered) # [2, 4]
리스트 컴프리헨션으로도 동일 작업을 표현할 수 있습니다. 팀 규칙/가독성에 맞춰 선택한다.
mapped2 = [x * 2 for x in numbers]
filtered2 = [x for x in numbers if x % 2 == 0]
간단한 프로그램은 함수만으로 효율적인 절차지향(procedure-oriented) 프로그래밍을 작성할 수 있다.
하지만 프로그램이 커지면 객체(object)의 틀(뼈대)인 클래스(class)를 사용한 객체지향(object-oriented) 프로그래밍이 필요하다.
클래스는 “데이터(속성) + 동작(메서드)”를 묶어 새로운 자료형을 정의한다. 생성형 AI 개발에서는 프롬프트, 응답, 점수 같은 구조화 데이터를 클래스로 관리하면 유용한다.
class Message:
def __init__(self, role: str, \
content: str, \
score: float | None = None):
self.role = role
self.content = content
self.score = score
def short(self):
return self.content[:20] + \
("..." if len(self.content) > 20 else "")
# 객체 생성
m = Message("assistant", "안녕하세요! 무엇을 도와드릴까요?")
print(m.role, m.short())
[Note]
파이썬에서 줄연속기호는 "\(백슬래시)"이다.
assistant 안녕하세요! 무엇을 도와드릴...
# @dataclass 데코레이터를 쓰기 위해 dataclasses 모듈을,
# 생성 시각을 담기 위해 datetime을 가져온다.
from dataclasses import dataclass
from datetime import datetime
# 데이터만 담는 클래스를 간단히 정의한다.
# @dataclass가 자동으로 __init__, __repr__, __eq__ 등을 만든다.
# 각 속성에 타입 힌트를 달았다(str, int, datetime).
# 런타임 강제는 아님 — 주로 타입체커/IDE용이다.
@dataclass
class LLMResult:
text: str
tokens: int
created_at: datetime
# LLMResult 인스턴스를 생성한다.
# created_at에는 현재 시각이 들어간다.
r = LLMResult(text="요약이다.", tokens=42, \
created_at=datetime.now())
# print는 두 필드만 출력한다.
print(r.text, r.tokens)
요약이다. 42