실제 이미지 인식 인공지능을 딥러닝 방법으로 만들 때는 합성곱 신경망(Convolutional Neural Network, CNN)을 사용한다. 인공신경망이 사람의 뇌가 작동하는 원리를 보고 만들었듯이, 합성곱 신경망 또한 시각 세포의 작동 원리를 본떠서 만들었다.
앞서 만들던 숫자 인식 인공신경망을 사용하여 똑바로 선 숫자 3을 학습시킨 인공지능은 기울어진 3을 보고 3으로 인식하지 못할 가능성이 있다. 하지만 우리 눈은 3이라는 숫자가 기울어졌든 아니든 그것이 3이라는 것을 안다.
그 이유로는 우리 눈은 전체에 대한 패턴을 인식하는 계층(layers)과 부분에 대한 패턴을 인식하는 계층(layers)이 서로 얽혀 있기 때문이다. 합성곱 신경망은 바로 이러한 원리에 착안하여 개발되었다.
앞에서 다양한 이미지의 픽셀값을 한 줄로 세워서 학습시켰다면, 합성곱 신경망은 이미지를 특정한 영역별로 추출하여 학습시킨다는 특징이 있다.
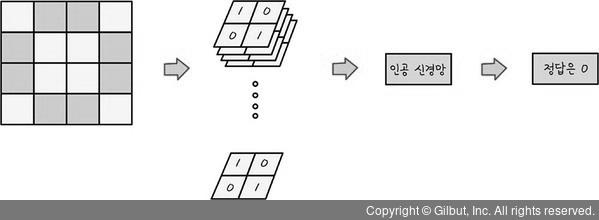
예를 들어, 다음 그림에서 살펴본 픽셀로 된 숫자 0을 2×2, 즉, 4칸씩 추출한다. 이러한 과정을 거쳐 부분의 특징을 찾아낼 수 있다.
합성곱(Convolution)에서 4×4 이미지를 2×2 이미지로 추출하는 모습
출처: 길벗
그런 다음 추출한 데이터를 인공신경망에 넣는다. 그리고 마지막 결괏값이 0이라고 알려 주면 인공신경망은 스스로 가중치와 편향을 바꾸어 가며 이 이미지가 숫자 0이라는 것을 학습한다.
전체와 부분을 함께 학습하는 CNN
출처: 길벗
실제로는 좀 더 복잡한 과정을 거쳐야 정확한 합성곱 신경망을 완성할 수 있지만, 이 그림은 합성곱 신경망이 데이터 각 부분의 특징을 잘 나타내는 신경망이라는 것을 나타내고자 단순하게 표현했을 뿐이다.
합성곱 신경망은 이미지의 특징을 파악하는 데 특화된 딥러닝 방법이다.
예를 들어 필기체 인식이나 차량 번호판 인식, 의료용 인공지능 개발, 물체 인식 등 이미지를 인식하는 다양한 분야에서 사용한다.
전연결(FC, Fully Connected) 층(Layer)만으로 구성된 인공 신경망의 입력 데이터는 1차원(배열) 형태로 한정된다.
한 장의 컬러 사진은 3차원 데이터이다.
하지만 배치 모드에 사용되는 여러 장의 사진은 4차원 데이터이다.
사진 데이터로 전연결 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화시켜야 한다. 사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수밖에 없다. 결과적으로 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율적이고 정확도를 높이는데 한계가 있다. 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델이 바로 CNN이다.
출처: http://taewan.kim/post/cnn/
합성곱 신경망을 정확하게 구현하려면 부분 데이터를 추출하는 과정에 좀 더 복잡한 단계가 필요하다. 더 자세히 설명하면 2×2 형태로 추출한 데이터를 어떤 값(필터, filter)으로 곱하고 특징적인 값을 찾아내는 과정이 필요하다.
이때 추출한 데이터를 필터와 곱할 때 합성곱 연산을 한다. 그래서 이 신경망 이름이 합성곱 신경망이다. 이러한 합성곱 연산을 사용하면 이미지의 어떤 (국소) 영역에 어떤 특징과 패턴이 있는지 알아낼 수 있다.
CNN은 인간의 시각 처리 방식을 모방한 신경망이다.
이미지 처리가 가능하도록 합성곱(Convolution) 연산을 도입하였다.
2016년에 공개된 알파고에도 CNN 기반의 딥러닝 모델이 이용되었을 정도로
CNN은 인공신경망 중에서도 가장 발전된 형태이다.
CNN의 가장 큰 장점은 필터를 학습을 통해 스스로 만든다는 것이다.
출처: https://aidev.co.kr/deeplearning/782
그렇다면 CNN에서 이미지 처리는 어떤 방식으로 진행될까?
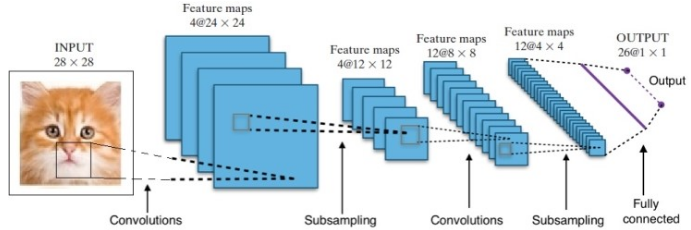
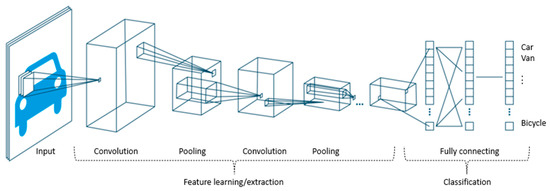
CNN은 다음과 같이 합성곱층, 풀링층, 완전연결층으로 구성되어 있다.
일반적인 CNN의 아키텍처(구조)는
(1) 합성곱,
(2) 활성화,
(3) 풀링 계층(레이어)을 반복하고
(4) 마지막에 완전 연결 계층을 사용한다.
출처: https://doi.org/10.3390/electronics12112402
합성곱층(Convolutional Layer) 합성곱층의 역할은 이미지를 분류하는 데 필요한 특징(Feature) 정보를 추출하는 것이다.
그렇다면 특징 정보는 어떻게 추출할 수 있을까? 바로 필터를 이용하면 된다.
필터(Filter)란 이미지의 특징을 찾아내기 위한 파라미터이며,
커널(Kernel)이라고도 한다.
필터는 하나 이상 사용할 수 있으며, 필터를 여러 개 사용하면 한 번에 여러 특징을 추출할 수 있다.
합성곱층에 필터가 적용되면 다음 그림과 같이 이미지의 특징들이 추출된 ‘특성 맵(Feature Map)’이라는 결과를 얻을 수 있다.
필터가 적용된 합성곱층
출처: https://mouryasashank.medium.com/convolutional-neural-networks-4a211e97c96f
풀링층(Pooling Layer) 풀링층은 합성곱층의 출력 데이터(특성 맵)를 입력으로 받아서
출력 데이터인 활성화 맵(Activation Map)의 크기를 줄이거나
특정 데이터를 강조하는 용도로 사용된다.
풀링층을 처리하는 방법으로는 최대 풀링(Max Pooling)과 평균 풀링(Average Pooling), 최소 풀링(Min Pooling)이 있다. 다음 그림과 같이 정사각 행렬의 특정 영역에서 최댓값을 찾거나 평균값을 구하는 방식으로 동작합니다.
풀링층 처리 방법
출처: https://doi.org/10.1016/j.jestch.2020.01.006
완전연결층(Fully-connected Layer) 완전연결층은 합성곱층과 풀링층으로 추출한 특징을 분류하는 역할을 한다.
CNN은 합성곱층에서 특징만 학습하기 때문에 DFN이나 RNN에 비해 학습해야 하는 가중치의 수가 적어
학습 및 예측이 빠르다는 장점이 있다.
최근에는 CNN의 강력한 예측 성능과 계산상의 효율성을 바탕으로 이미지뿐만 아니라
시계열 데이터에도 적용해 보는 연구가 활발히 진행되고 있다.
지금까지 배운 CNN을 정리하면 다음과 같다.
일반적인 인공신경망 모델은 완전연결층으로 이루어져 있다.
문제는 완전연결층 특성상 1차원 데이터만 입력으로 받는다는 것이다.
컬러 사진 데이터는 3차원 데이터이므로, 3차원 데이터를 완전연결층으로 구성된 신경망으로
학습시키려면 3차원의 데이터를 1차원으로 평면화시켜야 한다.
이때 이미지에 대한 공간 정보가 유실되어 특징을 잘 추출하지 못하면 학습에 비효율적일 수 있는데,
CNN은 이러한 문제를 해결할 수 있는 모델이다.