딥러닝(Deep Learning)은 인공신경망(Artificial Neural Network, ANN)을
기반으로 한 머신러닝의 한 분야로 심층학습이라고도 한다.
다층 신경망(Deep Neural Network, DNN)을 활용하여 데이터를 학습하는 알고리즘의 집합이다.
(1) 딥러닝이란?
1) 개요
딥러닝은 머신러닝의 하위 분야로, 인공신경망을 기반으로 다층 구조의 신경망을 통해 데이터를 학습하는 방식이다.
그림 1. 머신러닝과 딥러닝의 학습 차이
출처: 서지영, 난생처음 인공지능 입문(2판), 한빛미디어, 2024
딥러닝 네트워크는 입력층(Input Layer), 은닉층(Hidden Layers), 출력층(Output Layer)으로 구성된다.
2) 개발 과정
인공신경망(ANN)의 은닉층을 여러 개로 해서 깊게 만든 것이 심층 신경망이며, 이 심층 신경망을 학습시키는 과정을 딥러닝이라고 한다.
숫자를 인식하는 인공지능 개발을 예로 들어 보자.
컴퓨터 관점에서 보면 다음 그림의 왼쪽처럼 숫자 0의 이미지도 픽셀로 되어 있다. 이 이미지에서 각 픽셀은 하나하나의 점으로 되어 있지만, 컴퓨터는 이 점을 (256컬러: 0 ~ 255의 숫자 중 하나의) 숫자로 인식한다. 검은색은 0, 흰색은 255를 나타낸다. 회색은 검은 정도에 따라 1 ~ 254개의 숫자 중 하나로 표현한다.
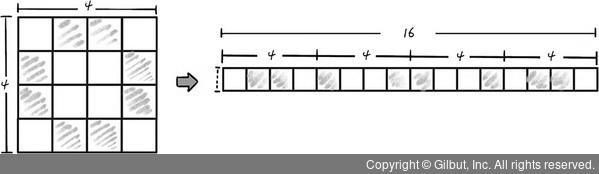
이 이미지를 인식하는 인공지능은 기본적인 인공신경망으로 만들 수 있다. 픽셀을 입력값으로 인공신경망에 넣으면 된다. 이때 가장 간단한 방법은 다음 그림과 같이 이미지의 픽셀을 한 줄로 세우는 것이다.
2차원 숫자 0(4x4 배열)을 1차원 숫자(1x16 배열)로 변경하기
출처: 길벗
[Note] 픽셀(pixel)
컴퓨터 이미지를 구성하는 하나하나의 점
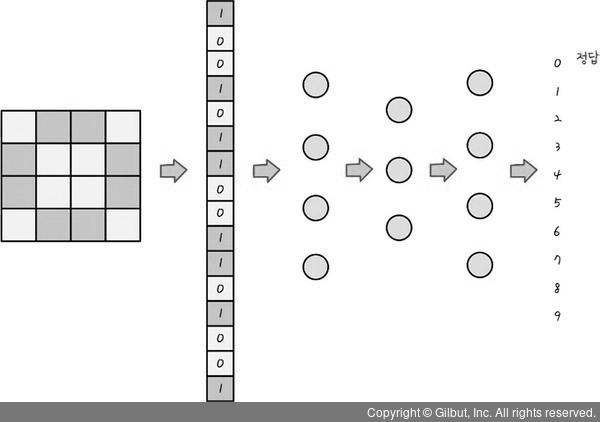
그런 다음 이 16개의 숫자를 인공신경망에 넣는다. 마지막 결괏값이 0이라고 알려 주면 인공신경망은 스스로 가중치와 편향을 바꾸어 가며 이 이미지가 숫자 0이라는 것을 학습한다.
216개의 숫자를 인공신경망에 넣어 학습한 후 정답 결과 도출
출처: 길벗
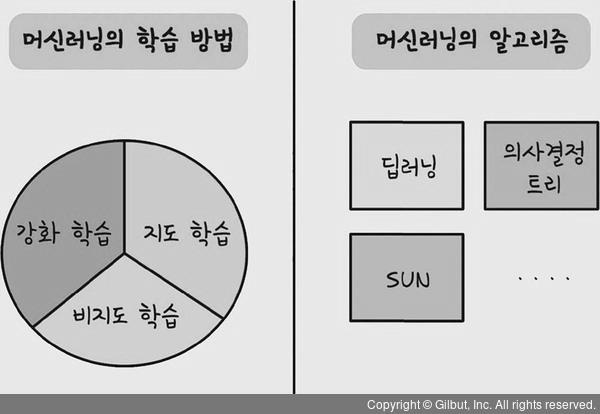
머신러닝의 학습 방법에는 지도학습, 비지도학습, 강화학습이 있다. 그렇다면 딥러닝도 학습 방법이 있을까? 딥러닝은 인공신경망을 사용한 머신러닝의 알고리즘 중 하나이다. 이렇게 머신러닝의 다양한 영역 중 하나인 딥러닝에도 지도학습, 비지도학습, 강화학습처럼 다양한 학습 방법이 있다.
앞에서 예를 든 것은 정답이 있는 데이터를 학습했기 때문에 지도학습 방법의 딥러닝이다. 딥러닝에도 비지도학습 방법의 딥러닝과 강화학습 방법의 딥러닝이 있다. 비지도학습 방법의 딥러닝에는 오토인코더, 생성적 적대 신경망(GAN) 등이 있다. 강화학습 방법을 사용한 딥러닝은 Deep Q-Network 딥러닝 모델도 있다.
머신러닝 학습방법 vs 머신러닝 알고리즘
출처: 길벗
3) Word Embedding (워드 임베딩)
워드 임베딩은 단어를 벡터로 표현하는 방법이다.
즉, 기계가 사람의 언어를 이해할 수 있도록 변환해 준다고 이해하면 된다.
대표적인 방법들은 다음과 같다.
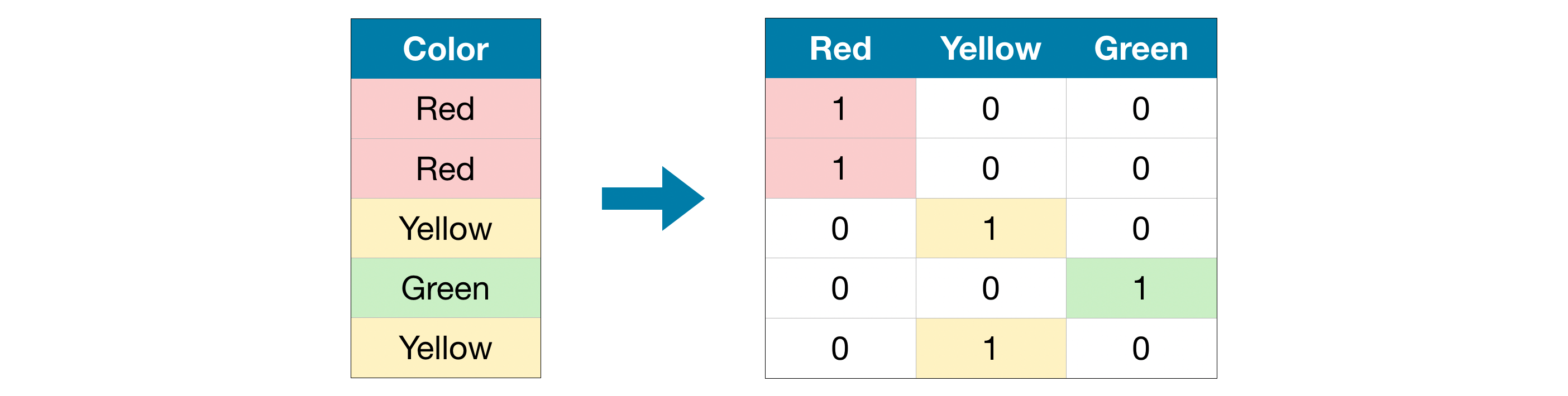
다음 그림은 팀 이름을 포함하는 3개의 범주형 변수를 0과 1 값만 가지는 새로운 3개의 변수들로 변환하기 위해
원-핫 인코딩을 수행하는 방법을 보여준다.
How to Perform One-Hot Encoding in Python
출처: https://www.statology.org/one-hot-encoding-in-python/
[Note] 원-핫 인코딩의 의미?
▪ 원(One): 변환된 벡터에서, 해당 범주에 해당하는 위치는 1로 표시.
▪ 핫(Hot): 그 위치의 값이 1일 때, 그 값이 "활발히 활성화(Hot)"됨.
▪ 나머지 위치들: 0으로 채워지므로, 해당 클래스가 "비활성화"됨.
[Note] AI에서 원-핫 인코딩을 사용하는 이유?
▪ 대부분의 AI 알고리즘은 숫자 입력만 처리할 수 있다.
▪ 1, 2, 3과 같은 범주의 순서에 따른 왜곡을 방지한다.
▪ 원-핫 인코딩은 서로 직교하므로, 모델 범주들을 독립적으로 학습시킬 수 있다.
Word2Vec (워드투벡터) 워드투벡터는 비슷한 문맥(context; 콘텍스트)에 등장하는 단어들은
유사한 의미를 지닌다는 이론에 기반하여
단어를 벡터로 표현해 주는 기법이다.
‘주변 단어를 알면 특정 단어를 유추할 수 있다’라는 원리를 기반으로 한 것으로,
대표적인 모델로는 CBOW(Continuous Bag-Of-Words)와 Skip-gram이 있다.
CBOW : 전체 콘텍스트로부터 특정 단어를 예측하는 것
예) 철수는 ◯◯◯를 구매했다.
Skip-gram : 특정 단어로부터 전체 콘텍스트의 분포(확률)를 예측하는 것
예) ◯◯◯ 도서 ◯◯◯
TF-IDF TF-IDF는 단어마다 가중치를 부여하여 단어를 벡터로 변환하는 방법이다.
여기서 사용되는 TF-IDF의 의미는 다음과 같다.
TF (Term Frequency) 특정 문서에서 특정 단어가 등장하는 횟수
예) ‘딥러닝’이라는 단어가 문서에서 3번 등장하면 TF는 3이 됨
DF (Document Frequency) 특정 단어가 등장한 문서의 수
예) ‘딥러닝’이라는 단어가 문서1과 문서2에서 언급되었다면 DF는 2가 됨
IDF (Inverse Document Frequency) DF에 반비례하는 수
TF-IDF의 경우, ‘은’, ‘는’, ‘이’, ‘가’와 같은 조사는 등장 빈도수가 높기 때문에
IDF는 작은 값을 갖게 된다.
따라서 조사의 가중치는 낮다. 즉, TF-IDF를 통해 단어에 대한 중요도를 알 수 있다.
Fasttext Fasttext는 페이스북에서 개발한 워드 임베딩 방법이다.
Fasttext는 단어를 벡터로 변환하기 위해 부분 단어(Sub Words)라는 개념을 도입한다.
부분 단어를 이해하기 위해서는 N-gram을 먼저 이해해야 한다.
N-gram은 문자열에서 N개의 연속된 요소를 추출하는 방법이다.
예를 들어, ‘Best books about AI’를 3-grams(트라이그램; Trigram)를 이용하여
부분 단어로 표현하면 다음과 같다.
"Best books about AI" → "Best books about", " books about AI"
부분 단어를 사용하면 워드투벡터에서 문제가 되는 ‘Out of Vocabulary (모르는 단어)’ 문제를
해결할 수 있기 때문에 임베딩에서 많이 사용되는 모델 중 하나이다.
여기서 Out of Vocabulary 문제란 입력 단어(혹은 문장)가 데이터베이스에 없어서 처리할 수 없는 문제를 뜻한다.
워드 임베딩 관련해서는 GloVe, Elmo 등 다양한 모델이 있으며
성능이 우수하기 때문에 많이 사용되고 있다.
(2) 딥러닝 vs 인공신경망
딥러닝 모델에서는 각 노드를 뉴런(Neuron)이라고 하며, 노드 간 연결을 에지(Edge)라고 한다.
각 뉴런은 입력 값을 받아들여 가중치(weight)를 적용하고, 편향(bias)을 더한 후 활성화 함수를 통과시켜 출력을 생성한다.
딥러닝 모델이 깊어질수록 역전파(Backpropagation) 과정에서 기울기(Gradient)가 소실되는 문제가 발생한다.
이 문제는 다음과 같이 설명할 수 있다.
\[ \text{오차} = \text{출력 값} - \text{실제 정답} \]
이 오차를 최소화하기 위해 매개변수를 조정하지만, 층이 깊어질수록 곱해지는 값이 작아져 기울기가 소실된다.
딥러닝 신경망의 역전파(Backpropagation) 과정에서, 출력층에서 입력층 방향으로 갈수록 기울기(Gradient) 값이 점점 작아져 0에 수렴하면서, 초반 층의 가중치가 제대로 업데이트되지 않아 학습이 멈추는 현상이다. 이는 주로 시그모이드(Sigmoid)나 Tanh 같은 활성화 함수의 도함수 값이 곱해지면서 발생하며, 신경망이 깊어질수록 학습 효율이 떨어지는 주요 원인이 된다.
역전파 과정에서 기울기가 소멸되거나 발산되는 문제 발생
출처: https://ljyong.tistory.com/47
2) ReLU 활성화 함수
ReLU(Rectified Linear Unit) 활성화 함수는 기울기 소실 문제를 해결하는 데 효과적이다.
ReLU의 도함수는 다음과 같이 정의된다.
\[ f(x) = \max(0, x) \]
이 함수는 0 이하의 값에서는 0을 출력하고, 0보다 크면 1의 기울기를 유지한다.
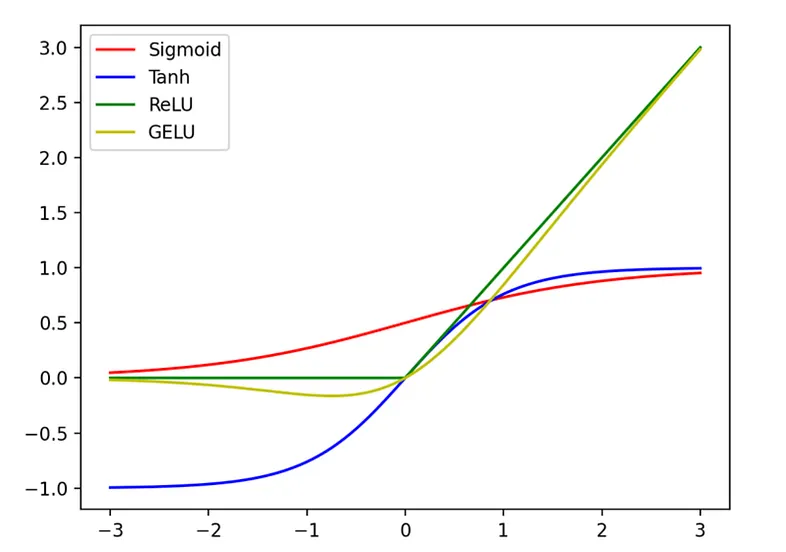
GeLU ~ A smoother ReLU
출처: https://medium.com/better-ml/relu-vs-gelu-d322422f5147
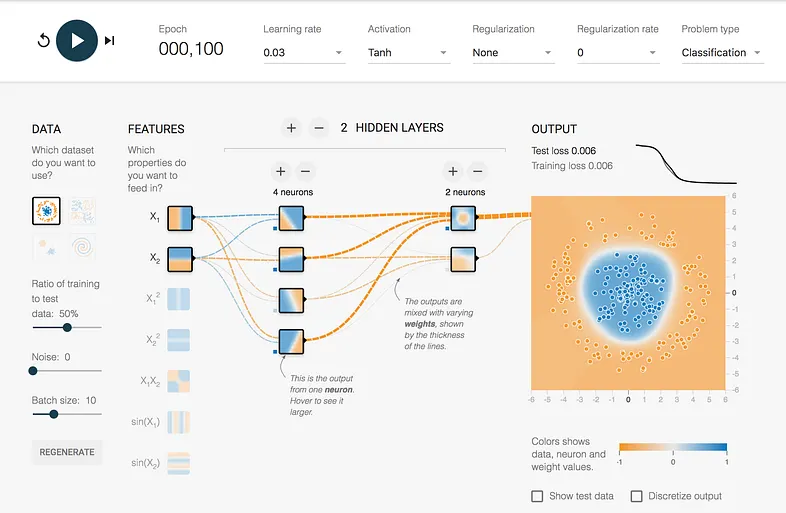
웹 브라우저에서 TensorFlow Playground에 접속한다.
초기 화면에는 데이터(DATA), 특성(FEATURES), 은닉층(HIDDEN LAYERS), 출력(OUTPUT) 영역이 배치되어 있으며,
분류(classification)를 기본 문제로 제공한다.
텐서플로 플레이그라운드로 딥러닝 이해하기
출처: https://medium.com/
2) 시작 버튼 클릭하기
▶ 버튼을 누르면 학습이 진행되며 에포크(epoch) 카운터가 증가한다. 학습 중에는 손실값의 변화를 통해
모델 수렴 여부를 확인할 수 있다. 손실이 일정 수준에서 더 이상 줄어들지 않으면 과대적합 혹은 한계에 도달한 것이다.
[Note] 1 에포크(epoch) = 데이터셋 전체 1회 학습
3) 출력 부분 살펴보기
OUTPUT 패널에는 결정 경계와 데이터 분포가 실시간으로 갱신된다. 학습 데이터와 검증 데이터는 서로 다른 색으로 표기되며,
Training loss와 Test loss 곡선을 통해 과적합 여부를 가늠할 수 있다.
검증 손실이 학습 손실과 급격히 벌어지면 과적합 신호다.
4) 신경망의 구조 설계하기
은닉층의 개수와 각 층의 뉴런 수는 모델의 표현력을 좌우한다. 층과 뉴런을 늘리면 복잡한 경계를 학습할 수 있으나,
계산량 증가와 과적합 위험이 동반된다. 2‒3개 층, 층당 8‒12개 뉴런을 기준으로 시작한 뒤, 성능을 확인하며 조정한다.
5) 데이터 입력 형태 선택하기
기본 특성은 x₁, x₂이며, 필요에 따라 x₁·x₂, x₁², x₂²,
sin(x₁), sin(x₂) 등 파생 특성을 추가할 수 있다.
Ratio of training to test data(훈련/검증 비율), Noise(노이즈), Batch size, Epoch을 조절한 뒤
REGENERATE를 눌러 새 데이터를 생성한다.
6) 복잡한 형태의 데이터 구분하기
비선형 경계가 필요한 데이터의 대표 예로 나선형(spiral)이 있다. 데이터셋에서 Spiral을 선택하고
적절한 은닉층 구성과 파생 특성을 더하면 나선형에 가까운 결정 경계를 학습할 수 있다.
핵심: 입력 특성 선택이 성능을 크게 좌우한다. 무작정 층과 뉴런을 늘리는 것보다, 문제 구조에 맞는 파생 특성 설계가
더 큰 개선을 제공한다.
7) 텐서플로 플레이그라운드 2배로 즐기기
화면 상단의 하이퍼파라미터를 적절히 조정하면 탐구 효율이 높아진다.
Learning rate — 가중치 갱신 폭을 결정한다. 너무 크면 발산, 너무 작으면 수렴 지연이 발생한다.
Activation — 비선형성을 도입하는 함수다. ReLU, Tanh, 시그모이드 등으로 경계의 매끈함과 수렴 특성이 달라진다.
Regularization — 과적합을 줄이기 위한 항이다. L2 정규화를 사용하면 가중치가 과도하게 커지는 것을 억제한다.
Regularization rate — 정규화 강도(λ). 값을 키우면 경계가 과도하게 매끈해질 수 있으므로 손실 곡선을 보며 조정한다.
Problem type — 분류(classification)와 회귀(regression) 중 선택한다. 본 장에서는 주로 분류를 다룬다.