(출처: https://www.livescience.com/)
신경망(Neural Network)은 인간의 뇌에서 영감을 받아 개발된 머신러닝 모델로, 뉴런(Neuron)과 그 연결 구조를 모방하여 데이터를 처리한다.
신경망은 "입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)"으로 구성된다. 각 층의 뉴런들은 가중치(Weight)와 활성화 함수(Activation Function)를 사용하여 정보를 전달하고 변환한다.


인공신경망 방식으로 만든 인공지능에서는 입력한 데이터가 여러 레이어를 지나가면서 특정한 신호로 전달된다. 그러면 최종적으로 신호가 남자 쪽으로 가는지, 여자 쪽으로 가는지를 판단하여, 둘 중 어느 쪽으로 신호가 많이 가는지를 살펴본 후 신호가 많이 간 쪽 성별이라고 판단을 내린다.



뉴런의 가지돌기가 신호를 입력받음
입력된 신호를 가중치를 적용하여 합산
가중합(Weighted Sum)이란 입력값과 가중치를 곱한 뒤
편향(Bias)을 더한 값을 말한다.
출처: 나무위키
출처: 길벗
특정 임계값(역치; threshold; action potential)을 넘으면 신호가 전달됨

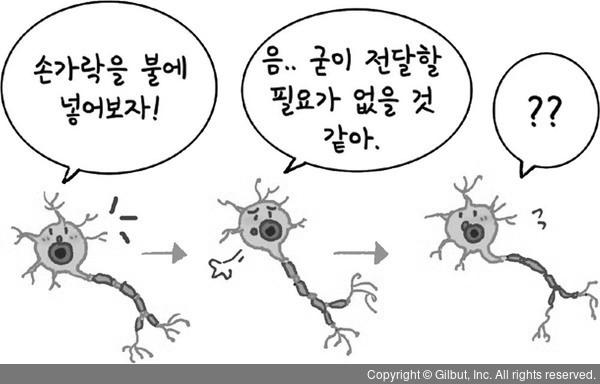
활성화된 신호가 다음 층으로 전달됨
딥러닝은 순전파, 손실함수, 옵티마이저, 역전파 과정을 거치면서 학습한다.▶ 순전파(Forward Propagation) [링크]

▶ 손실함수(Loss Function) [링크]


▶ 옵티마이저(Optimizer) [링크]

▶ 역전파(Backpropagation) [링크]
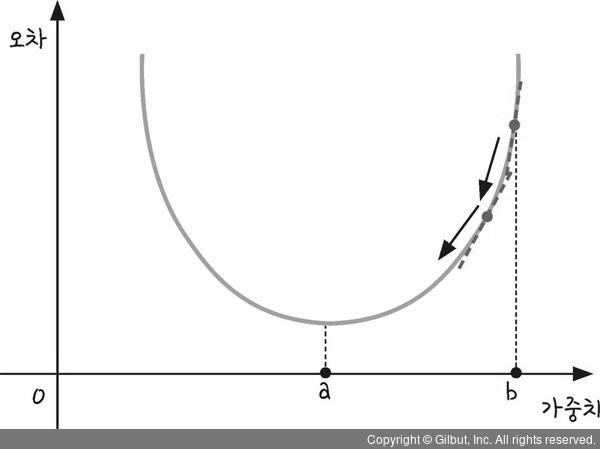
층이 하나만 있으면, 한 번의 경사하강법으로 뉴런과 뉴런을 연결한 가중치를 수정할 수 있다. 그러나 여러 개의 층이 있다면 문제가 복잡하다. 이렇게 많은 가중치를 어떻게 바꿀 수 있을까? 뒤에 있는 층의 가중치에서부터 앞에 있는 층의 가중치로 수정해 나가는 방법이 역전파 알고리즘이다.
역전파(Backpropagation; Chain Rule)란 오차(예측값과 실제값의 차이)를 역방향으로 전파시키면서 (출력층 → 은닉층 → 입력층) 가중치를 업데이트하는 것이다.


인공신경망은 인간의 뇌 신경망(Neural Network) 구조를 모방하여 정보를 처리하고 학습하는 알고리즘이다. 그 발전 과정은 수십 년에 걸쳐 점진적으로 이루어졌으며, 여러 시대적 전환점을 거치며 현재의 딥러닝 기술로 이어졌다.
1943년, 워렌 맥컬록(Warren McCulloch)과 월터 피츠(Walter Pitts)는 역사에 남을 논문을 발표한다. "A Logical Calculus of Ideas Immanent in Nervous Activity" 그들은 이 유명한 논문에서 우리 뇌에 있는 뉴런(neuron)을 간단한 모델로 변환하였으며, 이 모델은 '논리 단위'로 구성되어 모든 계산 작업을 수행할 수 있음을 보여주었다. 이 논문은 인간의 뇌를 논리적으로 설명할 수 있는 모델을 만들 수 있다는 가능성을 열었다는 점에서 기념비적이라 할 수 있다. 또한, 신경학과 촉발 발전한 컴퓨터 과학을 연결한 연구라는 점에서도 역사적 의의가 있다.
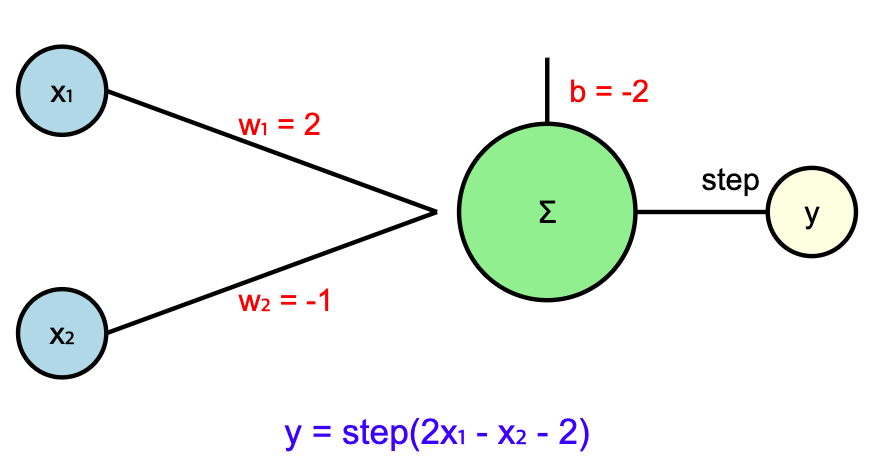
1958년, 프랭크 로젠블렛(Frank Rosenblatt)은 최초의 인공신경망 모델인 퍼셉트론(Perceptron)을 제안하였다.
퍼셉트론이란 신호(x1, x2)를 입력값으로 받아 가중치(w1, w2)를 곱하고, 그 결과를 합산한 뒤 활성화 함수를 통해 출력값(y)을 결정하는 알고리즘이다.

퍼셉트론은 간단한 선형 분류 문제를 해결할 수 있었으나, XOR 문제와 같이 선형적으로 분리되지 않는 데이터는 처리할 수 없다는 한계가 존재했다.

1969년, 마빈 민스키(Marvin Minsky)와 시모어 페퍼트(Seymour Papert)는 저서 『퍼셉트론』에서 퍼셉트론의 한계를 지적하며, 다층 구조가 필요함을 주장하였다. 즉, 당시의 퍼셉트론으로는 XOR 연산이 절대 불가능하며, 다층 퍼셉트론을 통해 XOR 연산에 대한 문제는 해결될 수 있지만, 각각의 가중치(Weight)와 편항(Bias)을 학습시킬 효과적인 알고리즘이 부재하였다.
이러한 배경 속에서 인공신경망에 대한 관심은 줄어들게 되었으며, 이 시기는 종종 "AI 겨울(AI Winter)"이라 불린다.
5년 후인 1974년, 폴 워보스(Paul Werbos)가 박사과정 논문에서 다층 구조의 가중치와 편항을 학습시키기 위한
역전파(Backpropagation)를 제안하였다.
기존의 전방향(Feedforward) 학습을 통해 가중치와 편향을 수정하는 것이 아니라,
전방향에 대한 학습 결과를 보고, 뒤로 가면서 가중치와 편향을 수정하는 알고리즘이다.
즉, 신경망의 오차(예측값 - 실제값)를 출력층에서부터 입력층으로 피드백하여
각층(Layer)의 가중치와 편향을 업데이트 하는 알고리즘이다.

1986년, 데이비드 럼멜하트(David Rumelhart)와 제프리 힌튼(Geoffrey Hinton) 등의 연구자들에 의해 또 다른 역전파(Backpropagation) 알고리즘이 제안되면서 다층 신경망의 학습이 가능해졌다. 이는 인공신경망의 연구에 다시 활력을 불어넣었다.
이후 인공신경망 연구는 큰 진전이 있었지만, 다음과 같은 이유로 긴
침체기에서 벗어나지 못했다.[AI의 2차 겨울]

깊었던 침체기에도 불구하고 인공신경망에 대한 연구는 꾸준히 진행되었다. 2006년, 역전파를 고안하였던 제프리 힌턴(Geoffrey Hinton) 교수는 "A fast learning algorithm for deep belief nets"라는 논문을 통해 가중치의 초기값을 제대로 설정하면 깊이가 깊은 신경망도 학습이 가능하다는 연구를 선보였다. 즉, 신경망을 학습시키기 전에 계층(예: 입력층, 은닉층) 단위의 학습을 거쳐 더 나은 초기값을 얻는 방식의 사전훈련(Pre-training) 방식을 제안한 것이다.
이어서 2007년에는 요슈아 벤지오(Yoshua Bengio) 팀이 "Greedy layer-wise training of deep networks"라는 논문을 통해 오토인코더(Autoencoder)를 사용한 좀 더 간단한 사전훈련 방법을 제안했다. 이러한 모든 노력을 통해 비로소 깊은 신경망에서도 학습이 가능하게 되었다.
그리고 이때부터 인공신경망(Neural)이라는 용어 대신 "딥(Deep)"이라는 용어를 사용하기 시작했다. 길고 긴 침체기 동안 인공신경망이라는 용어만 들어가도 논문 채택이 거절당할 정도로 부정적 인식이 강했기 때문에 사람들의 이목을 끌 수 있는 새로운 단어가 필요했기 때문이다. 그래서 2006년부터는 딥러닝(Deep Learning)이라는 용어가 사용되기 시작했다.
[Note] 사전훈련(Pre-training)이란?
선행학습이라고도 부르며,
다층 퍼셉트론에서 가중치와 편향을 제대로 초기화시키는 방법이다.
이후 컴퓨팅 파워의 향상, 대규모 데이터의 등장, GPU의 활용 등과 맞물려 2010년대에는 딥러닝(Deep Learning)이 급속도로 발전하였다. 딥러닝은 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에서 획기적인 성과를 이루었다.