RNN은 시계열 데이터와 같이 시간적으로 연속성이
있는 데이터를 처리하기 위해 고안된 인공신경망이다.
그렇다면 어떤 데이터를 시계열 데이터라고 하는가?
시계열 데이터는 일정한 시간 동안 계측되고 수집된 데이터를 의미한다.
시계열 데이터가 딥러닝 신경망의 입력값으로 사용될 때는
데이터의 특성상 앞에 입력된 데이터(전 시간의 데이터)가
뒤에 입력된 데이터(후 시간의 데이터)에 영향을 미친다.
그래서 입력된 데이터를 단순히 입력층, 은닉층, 출력층의 순서로 전파하기만 하는
DFN(심층 순방향 신경망)으로는 시계열 데이터를 정확히 예측할 수 없다.
3. RNN 구조는 DFN 구조와 어떻게 다른가?
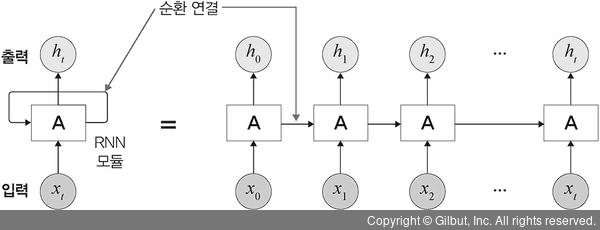
RNN은 은닉층의 각 뉴런에 순환(recurrent) 구조를 추가하여
이전에 입력된 데이터가 현재 데이터를 예측할 때 다시 사용될 수 있도록 하였다.
따라서 현재 데이터를 분석할 때
과거 데이터를 함께 고려하여 정확한 데이터 예측이 가능하다.
하지만 RNN 역시 신경망 층이 깊어질수록(은닉층 수가 많을수록)
먼 과거의 데이터가 현재에 영향을 미치지 못하는 문제가 발생한다.
이를 ‘장기 의존성(Long-Term Dependency)’ 문제라고 하며,
이를 해결하기 위해 제안된 것이 LSTM(장단기 메모리)이다.
RNN: 기억을 갖는 신경망 모델
RNN는 (forward NN이나 CNN과 달리)
데이터의 순차구조로 인식하기 위해 데이터를 시간 순서대로 하나씩 입력 받는다.
출처: 길벗
연속 데이터 결과를 예측하거나 분류할 때 사용된다.
순환 신경망이 기존의 일반적인 인공 신경망보다 뛰어난 점은
바로 전후 관계를 학습한다는 것이다.
일반적인 데이터 패턴을 학습하는 인공 신경망에서 한 단계 더 나아간 학습 방식이다.
순환 신경망은 다양한 곳에서 사용된다.
언어 번역에 사용된다. 전 세계에는 수많은 언어가 있다.
그리고 언어를 번역해 주는 다양한 앱과 서비스가 있다.
이러한 서비스는 순환 신경망을 이용해서 한 단계 더 발전하고 있다.
Hot Dog의 뜻은?
물론 ‘뜨거운 개’라는 뜻일 수도 있지만
우리가 먹는 음식인 ‘핫도그’를 뜻할 수도 있다.
그럼 어떻게 Hot Dog가 뜨거운 개인지, 음식인 핫도그인지를 구별할 수 있을까?
이럴 때는 문맥(Context, 글의 흐름)을 살펴보아야 한다.
사람들은 문맥을 살펴보며 이것이 뜨거운 개인지 핫도그인지를 쉽게 구별한다.
하지만 형태만 알고 있는 인공지능이라면 그 의미를 잘 구별해 내기가 어렵다.
또 ‘이’, ‘그’, ‘저’ 같은 대명사가 무엇을 의미하는지 문맥을 보지 않고서는 쉽사리 파악할 수 없다.
문맥을 학습할 수 있는 인공지능을 만드는 데 바로 이 순환 신경망을 사용한다.
실제로 구글의 번역 기술에 순환 신경망 기술을 사용하여 기존 방식보다
훨씬 뛰어난 번역 성능을 보여 주었다.
우리 주변에는 시간의 흐름 또는 연속된 관계를 가진 데이터가 많다.
이러한 데이터를 사용하여 인공지능 모델을 만들 때 바로 순환 신경망을 사용한다.
연속된 데이터 관계를 파악할 수 있는 순환 신경망을 체험해 보자.
스케치 RNN은 이름에서도 알 수 있듯이 순환 신경망을 사용한다.
스케치 RNN에서 사용하는 데이터는 퀵 드로우(Quick Draw)의 데이터셋이다.
퀵 드로우는 사용자가 그린 그림이 무엇인지 인공지능이 맞히는 게임이다. 퀵 드로우 데이터셋은 퀵 드로우를 체험하는 수많은 사람이 그린 그림 데이터로 구성되어 있으며, 어떤 순서로 그림을 그렸는지 포함되어 있다. 예를 들어 고양이를 그린다면 사람들은 대부분 얼굴을 그리고 귀를 그린 후 눈, 코, 입, 수염을 그리는 등 모두 같지는 않겠지만 일정한 순서에 따라서 그린 것이다.
이러한 순서 또한 연속된 데이터이다. 스케치 RNN은 이러한 순서 데이터를 학습했다. 사람들이 그린 순서대로 그림들을 학습했기 때문에 그림을 그리는 과정을 예측할 수 있다.
그래서 고양이를 그릴 때 누군가 얼굴을 그리면 자동으로 귀를 그려 준다. 또 귀를 그리면 자동으로 눈을 그려 준다. 물론 꼭 이 순서대로 하지는 않으므로 귀를 그리면 얼굴을 그리고, 눈과 코, 입을 그려 준다.